
5月1日
【开源】Mistral发布Mistral Medium 3.5,首次将指令遵循(Medium 3.1)、推理(Magistral)和编码(Devstral 2)三条模型线统一为单一128B稠密模型,256K上下文窗口,开源权重支持商业使用,最少4块GPU(80GB+显存)即可自部署。详情请参见
https://modelscope.cn/models/mistralai/Mistral-Medium-3.5-128B
【开源】蚂蚁百灵团队发布Ling-2.6-1T,万亿级综合旗舰模型,依托MLA与Linear Attention的Hybrid架构创新,强调多步执行稳定性与高智效比。在Artificial Analysis评测中仅用约16M output tokens即达到约34分Intelligence Index,与GPT-5.4(Non-Reasoning)同档。详情请见
https://www.modelscope.cn/models/inclusionAI/Ling-2.6-1T
5月5日
【闭源】谷歌更新文件搜索(File Search)功能,支持多模态搜索。现可使用gemini-embedding-2模型以原生方式嵌入图片并搜索图片,接地元数据新增media_id(用于视觉引用)和page_numbers(用于指示信息来源)。详情请参见
https://ai.google.dev/gemini-api/docs/file-search?hl=zh-cn
5月6日
【闭源】xAI发布grok-4.3,原生支持百万级(1M)上下文窗口,具备可配置推理能力(支持none/low/medium/high四档),并集成函数调用与结构化输出。定价方面,输入$1.25/百万tokens,缓存输入低至$0.20/百万tokens,输出$2.50/百万tokens。详情请参见
https://docs.x.ai/developers/models/grok-4.3
国内体验:https://nonelinear.com/static/models.html
【闭源】阿里发布fun-music-v1(百聆音乐生成大模型),支持输入开放性歌曲的创作要求或歌词,生成整首男/女声演唱的中文或英文歌曲,歌曲通俗易懂、情绪由浅入深,是人类灵感与大模型能力的完美结合。详情请参见
https://help.aliyun.com/zh/model-studio/fun-music
5月7日
【闭源】谷歌发布Gemini 3.1 Flash-Lite正式版(GA),该模型在速度、规模和成本效益方面进行了深度优化,是Gemini 3.1系列中面向高吞吐、低成本场景的轻量旗舰。详情请参见
https://ai.google.dev/gemini-api/docs/models/gemini-3.1-flash-lite?hl=zh-cn
国内体验:https://nonelinear.com/static/models.html
5月11日
【开源】面壁智能联合清华大学、OpenBMB开源社区正式发布并开源新一代端侧多模态大模型MiniCPM-V 4.6。该模型仅1.3B参数,面向手机、电脑等端侧设备优化,6G内存即可流畅运行,并在全球同尺寸多模态模型中取得领先表现,性能超越Qwen3.5-0.8B与Gemma4-E2B-it。详情参见
https://modelscope.cn/models/OpenBMB/MiniCPM-V-4.6
【开源】Jina团队正式发布jina-embeddings-v5-omni系列模型,将v5-text的向量能力扩展到图像、音频和视频,支持文本、图像、音频、视频在统一语义空间中检索,且文本向量与v5-text逐字节一致,已有文本索引无需重建即可平滑升级为多模态检索系统。其中small版本以较小参数规模追平更大体量四模态模型的平均表现,nano版本进一步面向轻量化部署,在文档检索场景中仍具备竞争力。详情请参见
https://modelscope.cn/models/jinaai/jina-embeddings-v5-omni-small
https://modelscope.cn/models/jinaai/jina-embeddings-v5-omni-nano
5月12日
【闭源】百度正式发布文心5.1模型,在继承文心5.0知识能力的基础上,显著优化参数效率与训练成本:总参数量压缩至约1/3,激活参数量压缩至约1/2,预训练算力成本仅为业界同规模模型约6%。技术上,文心5.1引入弹性预训练、分离式全异步强化学习训练,以及以多教师在线策略蒸馏为核心的多阶段后训练流程,在保持旗舰级能力的同时提升训练效率、推理成本与复杂长尾任务稳定性。详情请参见
https://ernie.baidu.com/blog/zh/posts/ernie-5.1-0508-release/
直接体验:https://nonelinear.com/static/models.html
【闭源】Anthropic为Claude Opus 4.7开放Fast mode研究预览能力。开发者可在API请求中设置model: "claude-opus-4-7"、speed: "fast",并添加fast-mode-2026-02-01 beta header,以获得显著更快的输出token生成速度。Fast mode运行的是同一模型权重和行为,不改变模型智能水平,主要提升输出token吞吐,适合对延迟敏感的Agent工作流和长输出场景。详情请参见
https://platform.claude.com/docs/en/build-with-claude/fast-mode
5月13日
【开源】腾讯开源Pixal3D,一款面向单图生成高保真三维资产的生成模型。不同于以往通过注意力机制松散注入图像特征的方法,Pixal3D借鉴三维重建思路,采用像素对齐的生成范式,直接在与输入视角一致的空间中生成三维结构,而不是先在标准空间中合成再回贴纹理。详情请参见
https://modelscope.cn/models/TencentARC/Pixal3D
5月15日
【开源】蚂蚁百灵团队正式开源Ring-2.6-1T,一款面向真实复杂任务场景的万亿级旗舰思考模型。与单纯堆参数或刷榜不同,Ring-2.6-1T更强调Agent工作流、工程开发、科研分析等长链路生产任务中的稳定执行能力,模型能力从“理解任务”进一步走向“持续推进任务”。底层训练方面,Ring-2.6-1T采用异步Async RL训练架构,将策略采样与参数更新解耦,并结合棒冰算法提升长周期强化学习稳定性,为万亿级思考模型训练提供了更可扩展的工程范式。详情请参见
https://modelscope.cn/models/inclusionAI/Ring-2.6-1T
5月19日
【闭源】xAI发布Grok Build 0.1,一款专门面向Agentic Coding场景训练的快速编码模型,目前处于Early Access阶段。该模型支持文本与图像输入、文本输出,拥有256K上下文窗口,并支持函数调用、结构化输出与推理能力,适合用于代码智能体、自动化开发流程、工程脚手架生成和多步骤编码任务。相比通用聊天模型,Grok Build 0.1的定位更偏向“为构建而生”的工程执行型模型,强调在真实开发链路中的速度、工具调用和可编排能力。详情请参见
https://docs.x.ai/developers/models/grok-build-0.1
【闭源】谷歌发布Gemini 3.5 Flash正式版。作为Gemini 3.5系列中面向智能体时代打造的高性能模型,Gemini 3.5 Flash在智能体任务、编码任务、多步工作流和长时程任务中持续提供前沿表现,同时兼顾更快速度与更高成本效率。该模型支持文本、图片、视频、音频和PDF输入,输出为文本,并支持批量API、上下文缓存、代码执行、文件搜索、函数调用、搜索接地、结构化输出、思考能力和URL上下文等能力,适合大规模部署子Agent、快速迭代编码循环和复杂生产任务。详情请参见
https://ai.google.dev/gemini-api/docs/models/gemini-3.5-flash?hl=zh-cn
国内体验:https://nonelinear.com/static/models.html
【闭源】阿里上线qwen3.5-livetranslate-flash-realtime,一款视觉增强型实时语音/音视频翻译模型。该模型可识别60种语言,并实时翻译为29种语言的音频,同时支持音频与图像输入,适用于实时视频流和本地视频文件翻译。同时,模型支持低延迟同传、自然拟人音色、热词配置和声音复刻,面向跨语言会议、直播、视频内容本地化等场景具备较强实用价值。详情请参见
https://help.aliyun.com/zh/model-studio/qwen3-5-livetranslate-flash-realtime
5月21日
【闭源】阿里发布qwen3.7-max,Qwen Max系列新一代旗舰模型。该模型仅支持纯文本输入,默认开启思考模式,并支持显式缓存,在编程、办公与生产力、长周期自主执行等方向均有明显增强。Qwen3.7-Max进一步强化了Agent能力,尤其适合代码Agent、复杂任务拆解、多轮执行和生产力工具场景,能够从单次问答走向更长链路的自主推进。详情请参见
https://qwen.ai/blog?id=qwen3.7
直接体验:https://nonelinear.com/static/models.html
【开源】腾讯混元正式开源全新翻译模型Hy-MT2,包含Hy-MT2-1.8B、Hy-MT2-7B、Hy-MT2-30B-A3B三个尺寸,分别面向端侧轻量部署、均衡性能与专业翻译效果。Hy-MT2支持33种语言互译,并面向真实业务场景、专业领域翻译和多语言指令遵循进行优化。详情请参见
https://modelscope.cn/collections/Tencent-Hunyuan/Hy-MT2
5月22日
【开源】美团LongCat团队正式开源LongCat-Video-Avatar 1.5,一款面向音频驱动人像视频生成的数字人视频模型。作为从开源SOTA迈向商业级应用的升级版本,LongCat-Video-Avatar 1.5在唇形同步、表情自然度、身份一致性、长视频稳定性、多人互动和推理效率上进行了全面优化。详情请参见
https://modelscope.cn/models/meituan-longcat/LongCat-Video-Avatar-1.5
5月26日
【开源】快手发布并开源Keye-VL-2.0-30B-A3B。该模型将DSA(DeepSeek Sparse Attention)引入多模态场景,支持256K超长上下文,并将长序列Prefill成本降低50%。模型重点优化长视频理解、时序推理和复杂视觉规划能力,在多项视频理解基准上达到30B级别SOTA,部分指标超过200B+开源模型。详情请参见
https://modelscope.cn/models/Kwai-Keye/Keye-VL-2.0-30B-A3B
5月28日
【闭源】谷歌正式发布gemini-3.1-flash-image(Nano Banana 2)和gemini-3-pro-image(Nano Banana Pro),即Gemini 3.1 Flash Image和Gemini 3.1 Pro Image的正式版(GA)。新版本面向图片生成与对话式图片编辑场景,提升了图片质量、主体一致性、宽高比稳定性和多语言文本渲染能力,并支持结合实时网络数据增强生成效果。详情请参见
https://ai.google.dev/gemini-api/docs/models/gemini-3.1-flash-image?hl=zh-cn
国内体验:https://nonelinear.com/static/models.html
【闭源】Anthropic发布Claude Opus 4.8,这是目前Claude系列中能力最强的通用可用模型。新模型默认支持1M token上下文窗口,最大输出128K tokens,并支持会话中途插入system messages,方便长程Agent任务动态调整指令。Claude Opus 4.8还引入adaptive thinking机制,仅在需要时触发推理,以减少不必要的思考token消耗;Fast mode也已在Claude API中开放研究预览。详情请参见
https://platform.claude.com/docs/en/about-claude/models/whats-new-claude-4-8
国内体验:https://nonelinear.com/static/models.html
【开源】阶跃星辰发布并开源Step 3.7 Flash,一款面向Agent生产化阶段的多模态Flash模型。模型采用稀疏MoE架构,总参数196B+1.8B(ViT),激活参数11B,最高生成速度可达400 Tokens/s。Step 3.7 Flash重点优化Agent、Coding、Search与多模态工作流,已适配Claude Code、OpenClaw、Hermes Agent等主流Agent框架,适合云端和本地部署。详情请参见
https://modelscope.cn/models/stepfun-ai/Step-3.7-Flash
直接体验:https://nonelinear.com/static/models.html

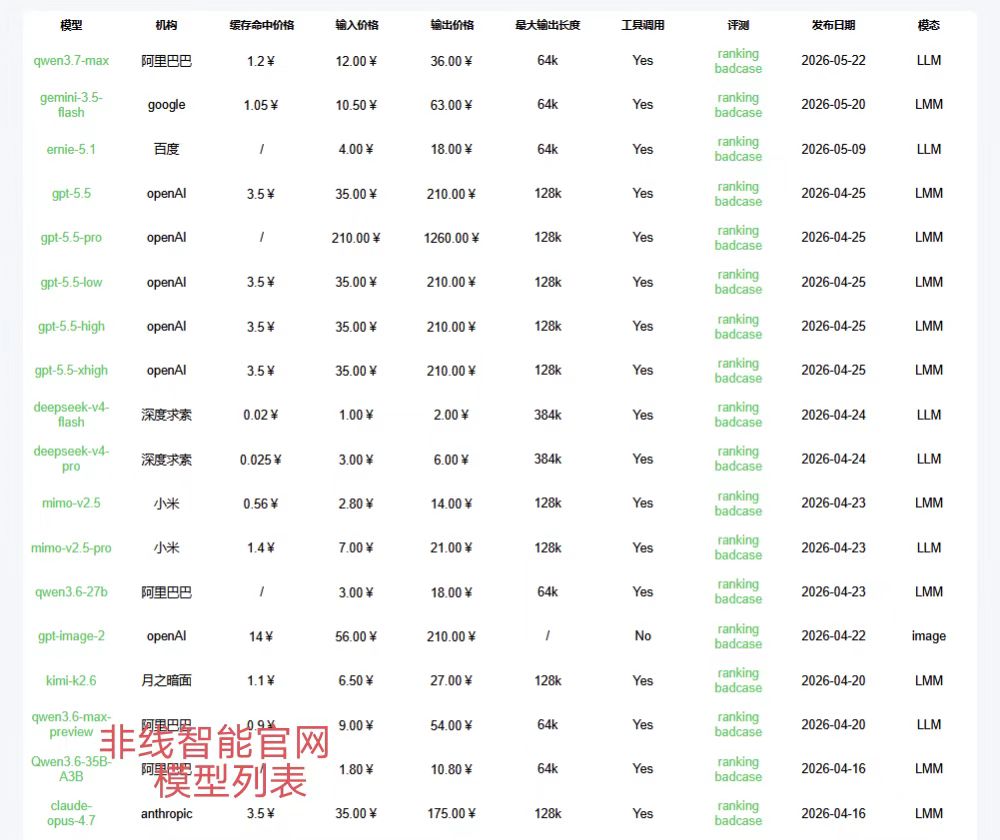
非线智能官网https://nonelinear.com 可连接超480+全球模型,支持一键Api聚合以及Api中转,提供稳定的企业级服务。 登录github账号,领20-50元体验金。
