
豆包近期发布了doubao-seed-1-8-251215新版本,官方重点强调其"更强Agent能力"和"多模态理解升级"。我们对doubao-seed-1-8-251215和上一代doubao-seed-1-6-251015进行了全面对比评测,测试其在准确率、响应时间、token消耗和成本等关键指标上的表现差异。
doubao-seed-1-8-251215版本表现:
测试题数:约1.5万
总分(准确率):71.7%
平均耗时(每次调用):33s
平均token(每次调用消耗的token):1186
平均花费(每千次调用的人民币花费):7.3
1、新旧版本对比
首先对比上个版本(doubao-seed-1-6-251015),数据如下:


*数据来源:ReLE评测https://github.com/jeinlee1991/chinese-llm-benchmark
*输出价格是"1元/M token "
整体性能显著提升:新版本准确率从63.5%提升至71.7%,增加了8.2个百分点,排名从第46位上升至第3位,进入榜单头部阵营。
Agent能力大幅增强:最值得关注的是"agent与工具调用"能力,从28.6%提升至63.1%,增幅达34.5个百分点。这与官方宣称的"Tool Use能力、复杂指令遵循能力、OS Agent能力都实现了大幅增强"相符,是本次升级的核心亮点。
推理能力增强:"推理与数学计算"能力从65.7%提升至74.4%,增幅达8.7个百分点。"金融"领域也有5.4个百分点的提升(80.6%→86.0%),体现了模型在专业推理场景的进步。
部分领域存在权衡:值得注意的是,新版本在"语言与指令遵从"领域出现了8.7个百分点的下降(75.8%→67.1%),"教育"领域也有2.2个百分点的回落(63.3%→61.1%)。这表明在重点强化Agent能力的过程中,部分传统能力有所调整。
响应速度明显提升:新版本平均耗时从51s缩短至33s,减少了约35%。
Token效率有所优化:每次调用平均消耗的token从1298降至1186,减少了约8.6%。结合速度提升,每千次调用费用从8.4元降至7.3元,成本下降约13%。
2、对比其他新模型
在当前主流大模型竞争格局中,doubao-seed-1-8-251215表现如何?我们选择了具有代表性的模型进行横向对比分析:

*数据来源:ReLE评测https://github.com/jeinlee1991/chinese-llm-benchmark
同成本档位对比
低成本档位表现突出:在10元/千次以下的成本区间内,doubao-seed-1-8-251215(71.7%,7.3元)准确率位居前列。对比hunyuan-2.0-thinking-20251109(71.9%,9.5元),准确率低0.2个百分点但成本低23%;对比qwen-plus-2025-07-28(67.6%,1.8元),准确率高出4.1个百分点但成本也相应更高。
速度优势突出:33s的响应时间在同档位中表现优异,快于doubao-seed-1-6-thinking-250715(37s)和hunyuan-t1-20250711(71s),仅略慢于hunyuan-2.0-thinking-20251109(28s)。
Token效率领先:1186的平均token消耗在同档位中处于领先水平,明显低于hunyuan-2.0-thinking-20251109(2544)和doubao-seed-1-6-thinking-250715(2162),token效率优势显著。
新旧模型对比
与同门模型对比:doubao-seed-1-8-251215(71.7%,第3位)与doubao-seed-1-6-thinking-250715(71.7%,第4位)准确率相当,但成本更低——7.3元 vs 15.6元,约为其47%,响应速度也更快(33s vs 37s)。
与国际模型对比:与gemini-3-flash-preview(71.5%,第5位)相比,准确率高0.2个百分点,成本约为其14%(7.3元 vs 53.5元),响应速度约为其两倍(33s vs 72s)。
与榜首差距:与榜首gemini-3-pro-preview(72.5%)相差0.8个百分点,与第二名hunyuan-2.0-thinking-20251109(71.9%)相差0.2个百分点。
开源VS闭源对比
成本控制接近开源水平:作为闭源商用模型,doubao-seed-1-8-251215的成本已接近开源模型水平。与开源的DeepSeek-V3.2-Think(70.9%,7.5元)相比,准确率高0.8个百分点,成本相当;与DeepSeek-V3.2-Exp-Think(70.1%,6.1元)相比,准确率高1.6个百分点,成本高1.2元。
Agent能力形成差异化:63.1%的Agent能力在主流模型中处于较高水平,这是豆包本次升级重点打造的差异化能力。
国产模型竞争力提升:从榜单来看,前五名中国产模型占据四席,体现了国产大模型在中文场景下的竞争力。不过需要指出的是,本评测侧重中文场景,模型在其他语言和专业领域的表现可能有所不同。
3、官方评测
豆包官方发布了Seed1.8的详细技术介绍,以下是官方公布的核心内容(原文链接:通用Agent模型Seed1.8正式发布):
通用Agent能力
官方表示,Agent能力的难点体现在多个层面:多任务并行处理(模型需要在多个任务之间做出判断,高效分配计算资源)、复杂指令遵循(在需要处理多个约束条件的任务中快速准确执行)、跨域知识迁移(在不同领域之间切换并完美执行任务)。Seed1.8在以上难点中都有所突破:
GUI Agent能力:评测结果显示Seed1.8具备业界领先的GUI Agent能力,较Seed1.5-VL进一步提升,并在电脑、网页、移动端三类环境中均展现出执行多步任务的可靠性。
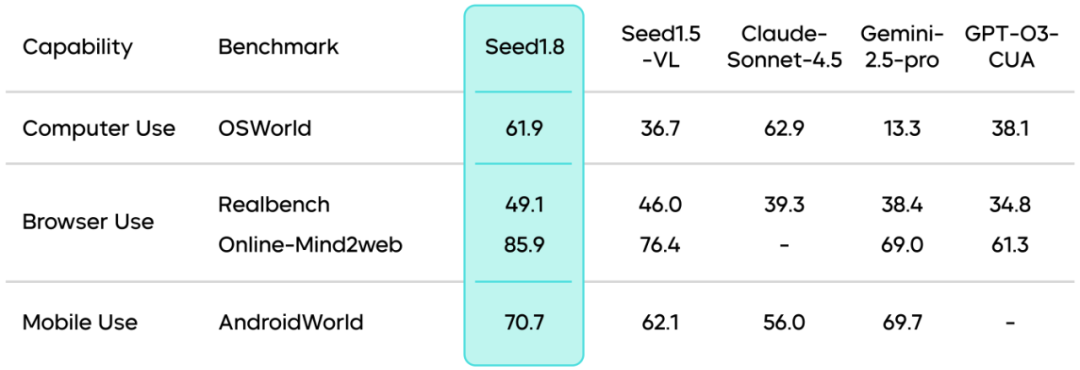
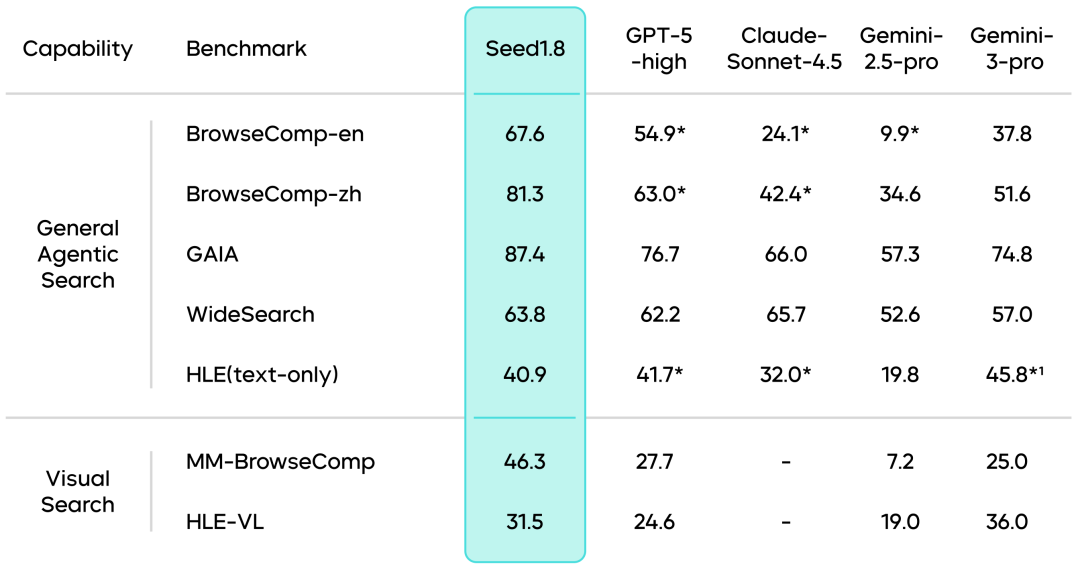
搜索任务能力:Seed1.8在多组公开Agent搜索评测基准中保持业界第一梯队水平,在BrowseComp-en基准测试中得分高达67.6,超过Gemini-3-Pro等其他顶级模型。
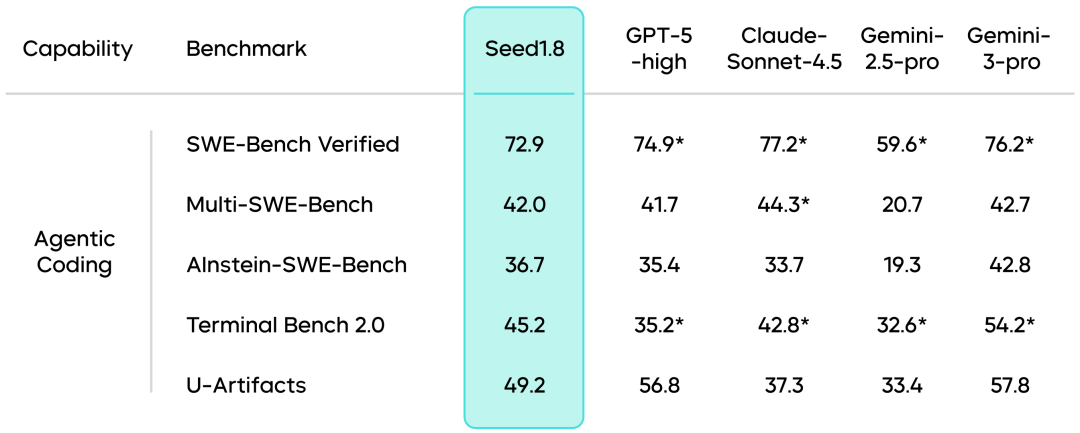
Agentic Coding能力:Seed1.8在Agentic Coding相关基准测试中展现出面向真实软件工程场景的稳定能力,具备在真实开发环境中持续推进任务的Agent编程能力,为复杂工程场景下的应用打下基础。
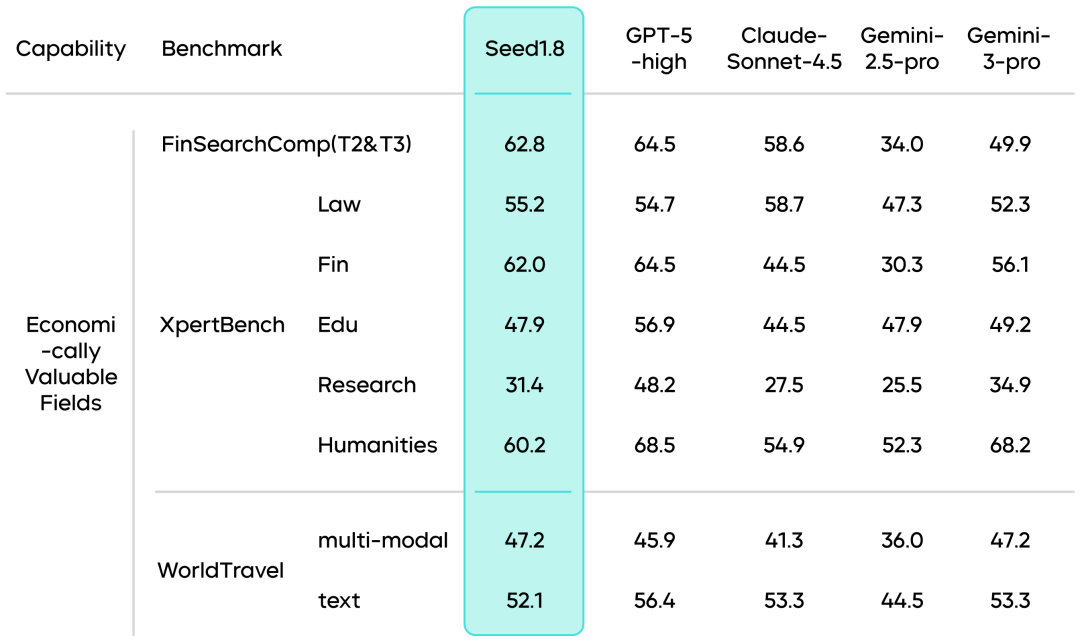
行业应用任务:FinSearchComp和XpertBench的测评显示,该模型在处理金融商业相关任务时相对稳定和高效。Seed1.8在WorldTravel多模态应用任务中得分达47.2,表明它在处理旅行规划、用户需求分析等真实场景需求时具有可靠性。
LLM能力评测
核心基础能力:在数学、推理和知识理解等核心基础能力维度上,Seed1.8整体水平接近业界顶级通用模型,在多组公开的大语言模型基准测试中保持稳定且具有竞争力的表现,处于业界第一梯队水平。
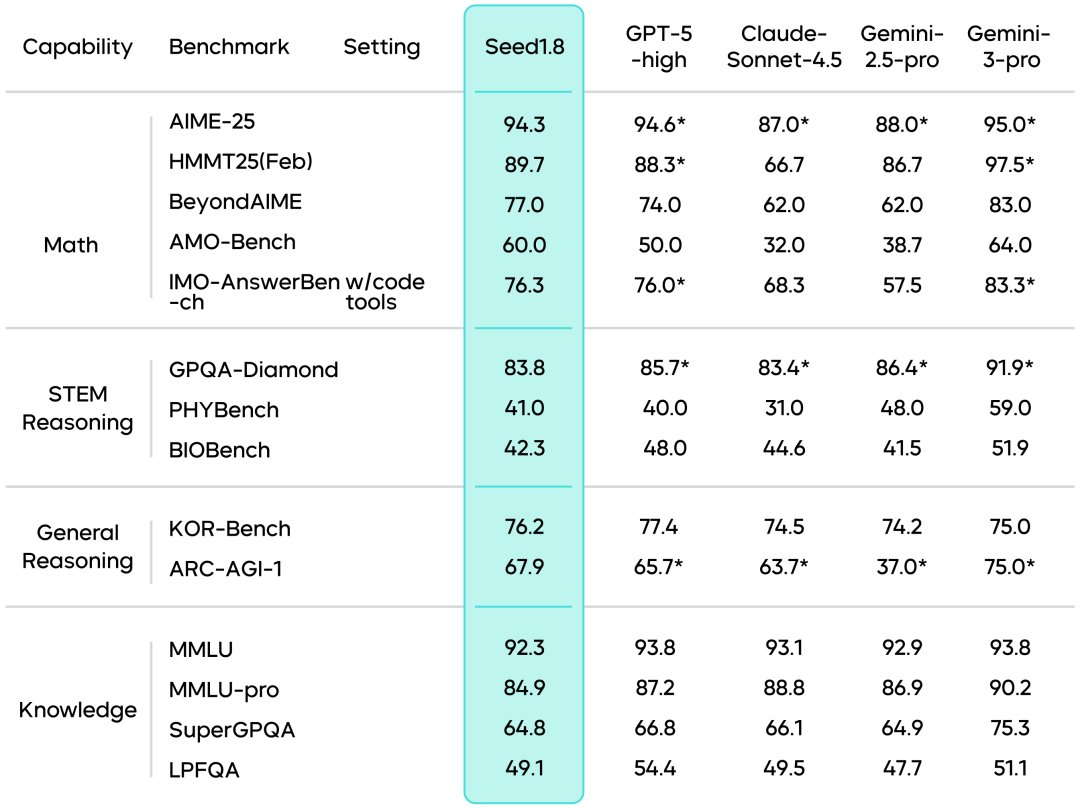
复杂指令遵循:在复杂指令遵循相关的基准测试中,Seed1.8展现出稳定的执行能力。这类任务通常包含多重约束、反向条件或长链路推理,要求模型在多步执行过程中持续保持对指令目标的准确理解。从结果来看,Seed1.8在多项复杂指令基准中保持了与业界领先模型接近的表现。
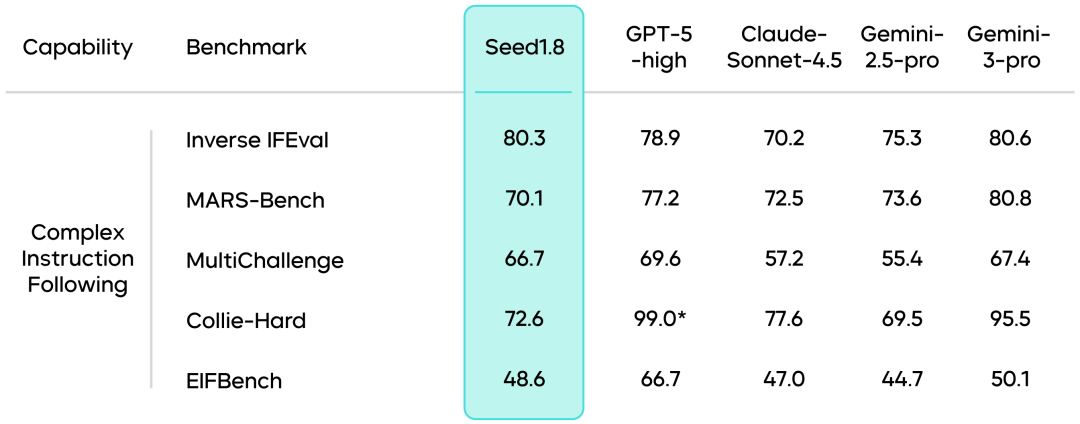
真实场景验证:Seed1.8进一步将能力验证扩展至由真实专家定义、具有明确经济价值的应用场景,包括教育辅导、客服问答、信息处理、意图识别、信息抽取以及多步骤复杂工作流等任务类型,验证了模型在真实使用环境中的适用性。
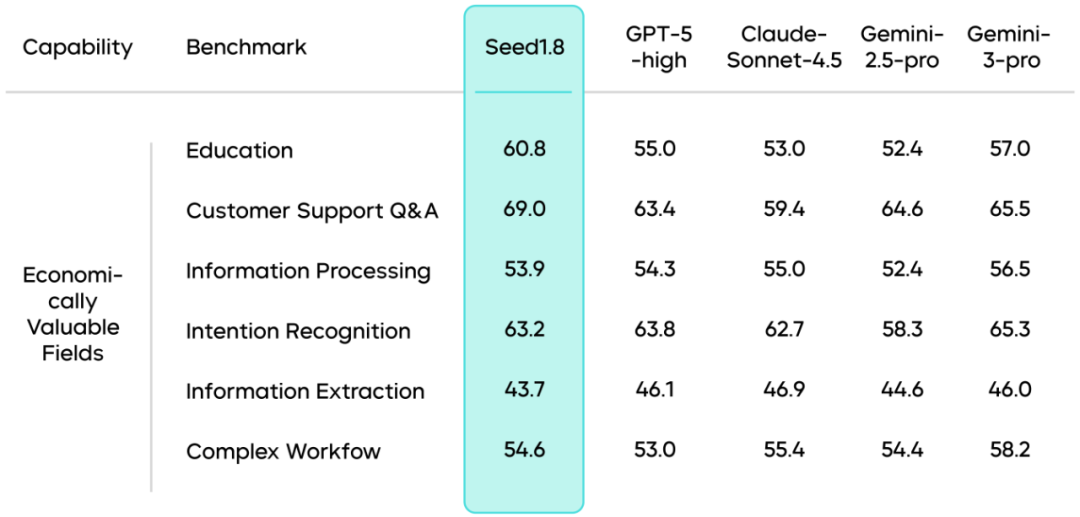
VLM多模态能力
整体表来看,Seed1.8在多个视觉语言基准测试中表现突出,在多模态推理任务中超越了前代模型Seed1.5-VL,在大部分任务中接近目前最先进的Gemini-3-Pro。
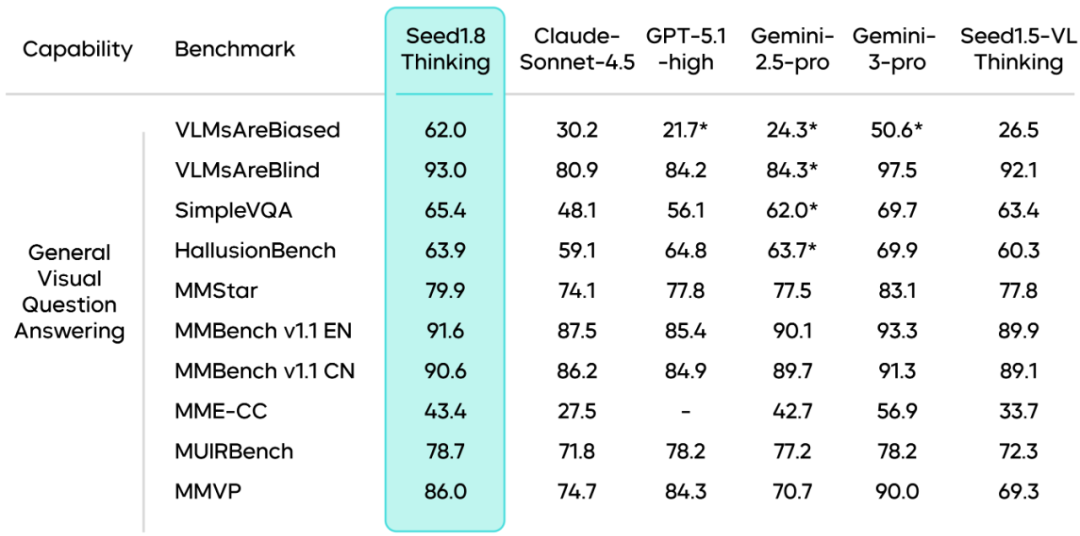
图像理解能力:在多模态推理类任务中,Seed1.8在被认为难度极高的视觉推理测试ZeroBench中获得11.0的最高得分,相比前代Seed1.5-VL成功解答问题数量大幅增加。在通用视觉问答任务中,Seed1.8在VLMsAreBiased基准测试中取得62.0的分数,大幅领先其他模型。
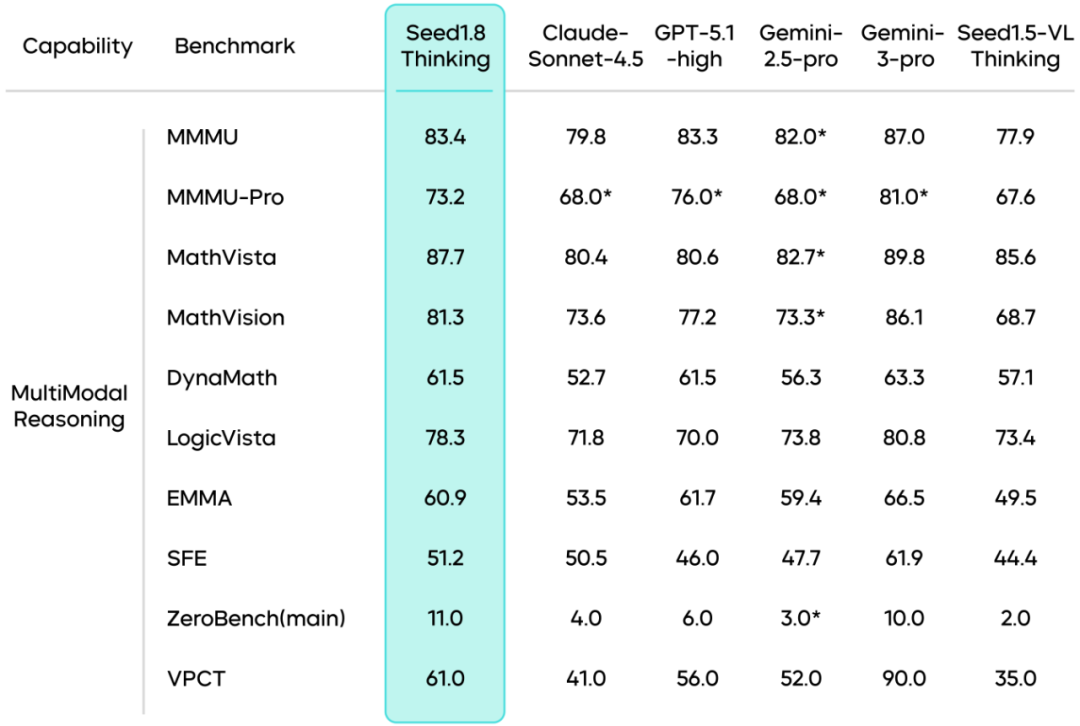
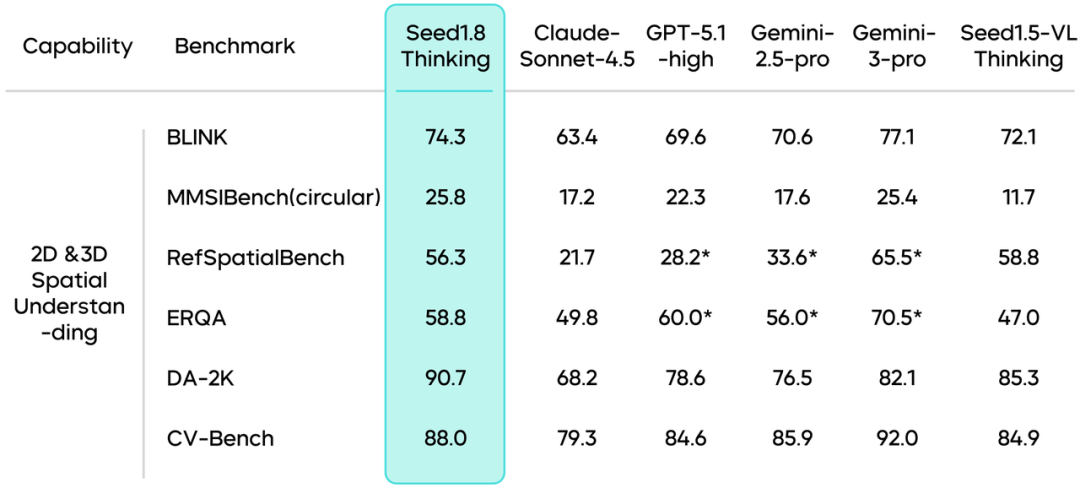
空间理解能力:Seed1.8在2D以及3D空间理解的多个基准测试中表现优秀,在处理3D空间理解和复杂任务时,特别是在动态和复杂数据集上,表现出较好的适应性和推理能力。
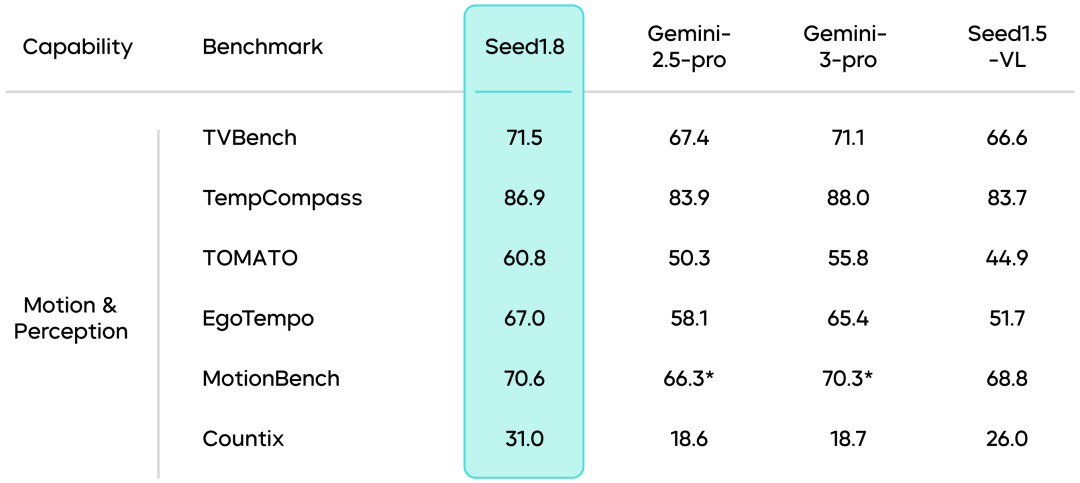
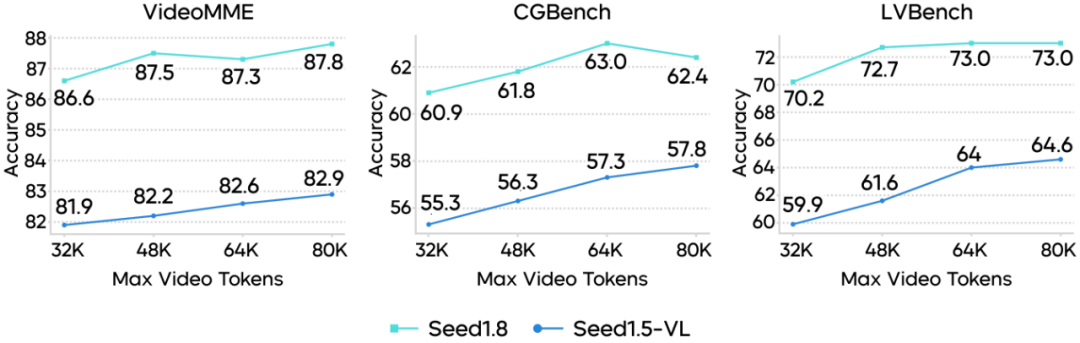
视频理解能力:Seed1.8在视频理解领域表现出色,尤其在视频推理、运动与感知、长视频理解等任务中展现出较强的适应性。在VideoMME中取得87.8的较高分数。Seed1.8加入了"VideoCut"视频工具调用能力,通过对部分片段慢放回看,可实现更加精准的长视频推理与高帧率运动感知。
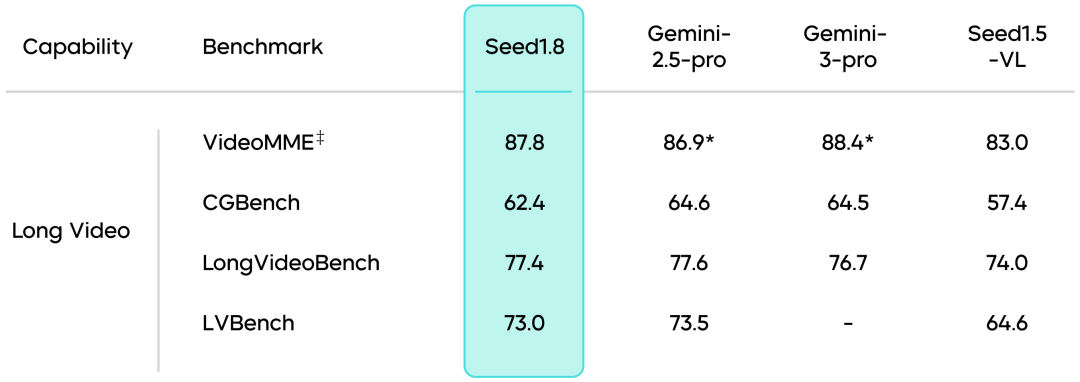
Token效率提升:在视频处理中,Seed1.8实现了Token Efficiency的显著提升,即便采用更低的Max Video Token配置,仍然可取得比Seed1.5-VL更好的表现,为用户提供更低延迟的实时视频处理体验。
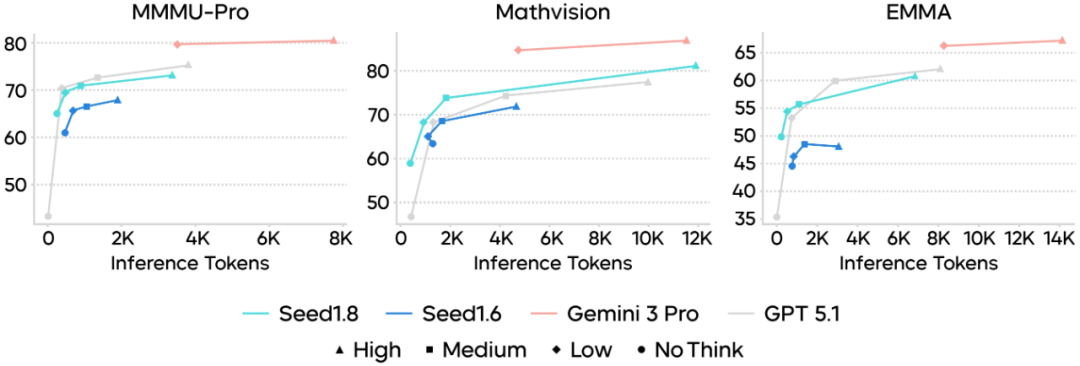
多种Thinking Modes:Seed1.8通过引入多种Thinking Modes,嵌入了动态调节思考深度的能力。用户可以根据任务的不同需求,灵活调整模型的推理深度和计算负载。
大模型/agent评测技术交流:关注公众号,发送消息"进群"
