
谷歌在这周发布了gemini-3-flash-preview新版本,官方称其"以不到gemini-3-pro四分之一的成本提供强大性能",并声称"在许多基准测试中超越了2.5 Pro"。我们对gemini-3-flash-preview和上一代gemini-2.5-flash进行了全面对比评测,测试其在准确率、响应时间、token消耗和成本等关键指标上的表现差异。
gemini-3-flash-preview版本表现:
测试题数:约1.5万
总分(准确率):71.5%
平均耗时(每次调用):72s
平均token(每次调用消耗的token):2731
平均花费(每千次调用的人民币花费):53.5
1、新旧版本对比
首先对比上个版本(gemini-2.5-flash),数据如下:


*数据来源:ReLE评测https://github.com/jeinlee1991/chinese-llm-benchmark
*输出价格是"1元/M token "
整体性能大幅跃升:新版本准确率从60.6%跃升至71.5%,提升了10.9个百分点,排名从第64位大幅攀升至第5位,有了质的飞跃。这一跃升幅度在近期发布的新模型中表现突出,说明谷歌在Flash系列上投入了大量技术优化。
教育领域提升最为显著:从细分领域来看,"教育"能力实现了最大幅度提升,从36.0%跃升至63.5%,增幅高达27.5个百分点,几乎接近翻倍。这一领域此前是gemini-2.5-flash的明显短板,新版本大幅补齐了这一弱项。
推理能力显著增强:"推理与数学计算"能力从67.5%提升至83.4%,增幅达15.9个百分点。"医疗与心理健康"(+15.1%)和"金融"(+13.7%)领域也有双位数的提升。
响应速度有所变慢:新版本平均耗时从40s增加至72s。这可能是gemini-3-flash-preview刚发布两天,访问量的激增导致服务器负载较高,实际稳定后的响应速度会快不少。
成本有所上升:每千次调用费用从43.2元增加至53.5元,增幅约23.8%。输出价格从18.125元/M token上调至21.3元/M token,token消耗也从2586增加至2731(+5.6%)。
2、对比其他新模型
在当前主流大模型竞争格局中,gemini-3-flash-preview表现如何?我们选择了具有代表性的模型进行横向对比分析:

*数据来源:ReLE评测https://github.com/jeinlee1991/chinese-llm-benchmark
同成本档位对比
50-100元档位竞争力突出:在50-100元/千次的成本区间内,gemini-3-flash-preview(71.5%,53.5元)以最低成本实现了最高准确率。对比gpt-5.1-medium(69.3%,87.9元),准确率高出2.2个百分点且成本低39%;对比Kimi-K2-Thinking(68.3%,89.2元),准确率高出3.2个百分点且成本低40%。
速度表现中规中矩:72s的响应时间在同档位中处于中等水平,快于gpt-5.1-medium(160s)和Kimi-K2-Thinking(333s),但慢于gpt-5.2-high(36s)。考虑到新模型服务器压力因素,后续速度会快不少。
Token效率有待提升:2731的平均token消耗在同档位中偏高,高于gpt-5.1-medium(1448)和gpt-5.2-high(1259),与Kimi-K2-Thinking(5732)相比则有明显优势。token效率直接影响长期使用成本,这是需要关注的优化方向。
新旧模型对比
官方宣称得到验证:谷歌声称gemini-3-flash-preview"在许多基准测试中超越了gemini-2.5-pro",我们的测试数据支持了这一说法。gemini-3-flash-preview(71.5%,第5位)确实超越了gemini-2.5-pro(68.9%,第12位),准确率高出2.6个百分点,且成本仅为其28%(53.5元 vs 189元)。
同门旗舰差距缩小:与同期发布的gemini-3-pro-preview(72.5%,第1位)相比,Flash版本仅落后1.0个百分点,但成本约为Pro版本的五分之一(53.5元 vs 247.3元),基本符合官方宣称的"不到四分之一成本"。
产品线跃升显著:从gemini-2.5-flash(第64位)到gemini-3-flash-preview(第5位),谷歌在一代产品内实现了59个排名的跃升,展现了强大的技术迭代能力,"Flash超越上代Pro"的产品策略得到验证。
开源VS闭源对比
国产闭源成本优势明显:与国产头部模型相比,gemini-3-flash-preview在成本上处于劣势。doubao-seed-1-8-251215(71.7%,7.3元)准确率相当但成本约为其14%;hunyuan-2.0-thinking-20251109(71.9%,9.5元)准确率略高且成本不到五分之一。不过需要指出的是,本评测侧重中文场景,模型在英文及其他语言、专业领域等的表现有所不同。
开源模型快速追赶:开源的DeepSeek-V3.2-Think(70.9%,7.5元)准确率仅低0.6个百分点,但成本优势达到7倍;DeepSeek-V3.2-Exp-Think(70.1%,6.1元)成本优势接近9倍。智谱GLM-4.6(68.1%,37.6元)作为开源模型也以更低成本提供了接近的性能。
差异化竞争是关键:从中文场景的测试数据来看,海外闭源模型的成本溢价正面临国产闭源和开源生态的双重竞争压力。gemini-3-flash-preview的优势可能更多体现在多模态处理、多语言支持、工具调用等差异化能力上,这些维度值得进一步评测验证。
3、官方评测
谷歌在官方博客中详细介绍了gemini-3-flash-preview的能力定位与评测数据,以下是官方公布的核心内容:
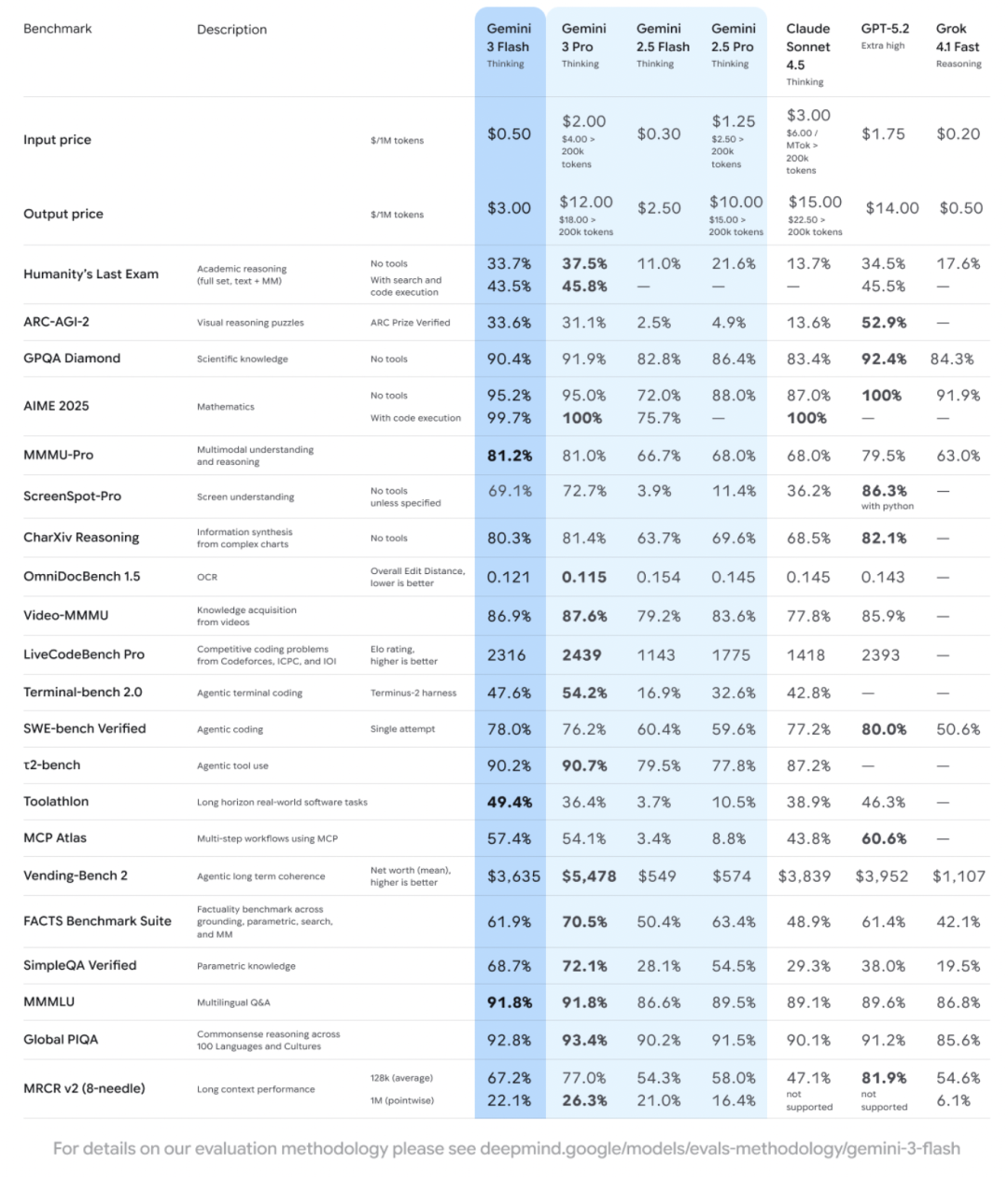
博士级推理能力:官方称gemini-3-flash-preview在博士级推理和知识基准测试中展现出前沿水平——GPQA Diamond达到90.4%,Humanity's Last Exam(无工具)达到33.7%,"可与更大规模的前沿模型相媲美"。
编码领域:gemini-3-flash-preview相比之前版本具有更强的编码和代理能力,支持快速迭代开发。在SWE-bench Verified上达到78%,超越了3 Pro的代理编码能力,同时运行更快。
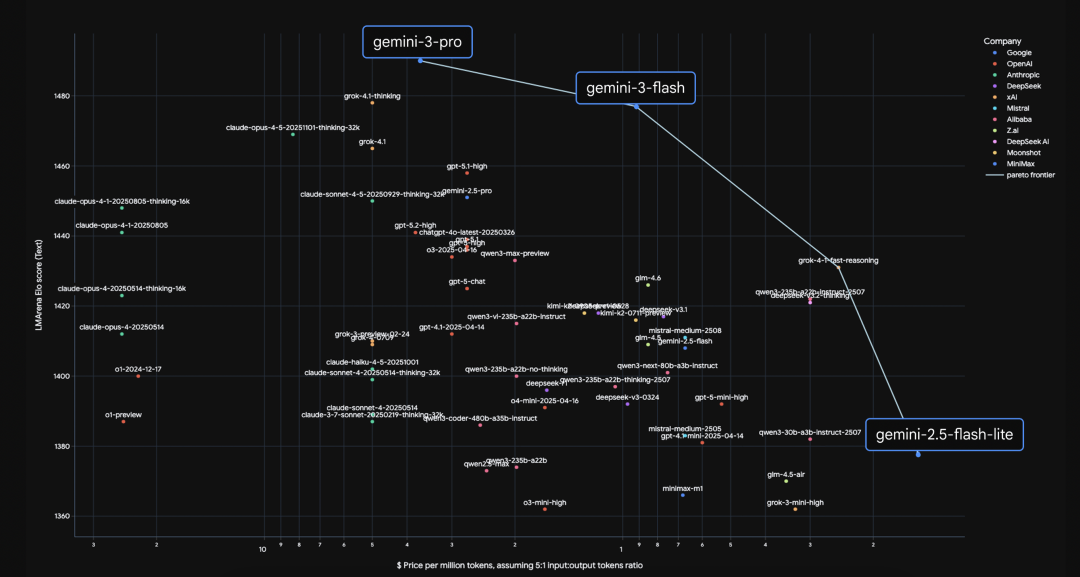
推动性能与效率的帕累托前沿:官方表示gemini-3-flash-preview"高效而不牺牲智能"。它在超越gemini-2.5-pro的同时速度快3倍(基于Artificial Analysis基准测试),成本仅为一小部分。即使在最低思考级别下,gemini-3-flash-preview也经常超越之前"高"思考级别的版本。官方特别说明,这里的性能以LMArena Elo分数衡量。
我们官网https://nonelinear.com/static/models.html已上线gemini-3-flash-preview,欢迎对比体验。同时,非线智能API支持Api聚合以及Api中转,提供稳定的企业级服务。个人中心 https://nonelinear.com/static/balance.html 登录github账号,领50元体验金
大模型/agent评测技术交流:关注公众号,发送消息"进群"
