
XAI近期发布了Grok-4-1-fast模型,官方定义为"针对高性能智能体工具调用进行优化的前沿多模态模型"。该模型支持思考模式(reasoning)和非思考模式(non-reasoning)两种版本。本次评测聚焦于思考模式版本grok-4-1-fast-reasoning,相比此前的grok-4-0709版本,新版本在响应速度上实现了显著优化,但在准确率方面出现了下降。我们对这两个版本进行了全面的对比评测,测试其在准确率、响应时间、token消耗和成本等关键指标上的表现差异。
grok-4-1-fast-reasoning版本表现:
测试题数:约1.5万
【总分】准确率:64.3%
平均耗时(每次调用):62s
平均消耗token(每次调用):2492
花费/千次调用(元):8.1
1、新旧版本对比
首先对比上个版本(grok-4-0709),数据如下:


*数据来源:ReLE评测https://github.com/jeinlee1991/chinese-llm-benchmark
整体性能表现分化:新版本准确率从61.2%提升至64.3%,提升了3.1个百分点,排名从第44位上升到第29位,64.3%的准确率在当前竞争格局中处于中等偏上游水平。
推理能力大幅跃升,但其他领域普遍下滑:最显著的提升来自"推理与数学计算能力",从63.7%跃升至78.1%,增幅达14.4个百分点,这与官方强调的"高性能"定位相符。然而,其他领域几乎全面下滑——"医疗与心理健康"下降4.7个百分点(75.0%→70.3%),"金融"下降4.5个百分点(75.1%→70.6%),"法律与行政公务"下降8.7个百分点(74.0%→65.3%),"语言与指令遵从"更是大幅下降11.8个百分点(64.6%→52.8%),表明新版本在优化推理能力的同时牺牲了其他专业领域的表现。
Agent能力显著增强:作为官方重点优化的方向,"agent与工具调用"能力从48.4%提升至65.4%,增幅达17.0个百分点,是除推理能力外提升最明显的领域,验证了"optimized for agentic tool calling"的产品定位。
速度大幅提升:每次调用的平均耗时从293s大幅缩短至62s,提速约78.8%,这是新版本最显著的优势之一,极大改善了用户体验。
成本控制成效显著:输出价格从108.75元/M token大幅下调至3.55元/M token,降幅达96.7%。尽管token消耗略有增加(2379→2492,+4.8%),但每千次调用的费用仍从241.5元暴降至8.1元,成本下降96.6%,实现了成本的革命性优化。
2、对比其他新模型
在当前主流大模型竞争格局中,grok-4-1-fast-reasoning表现如何?我们选择了具有代表性的21个模型进行横向对比分析:
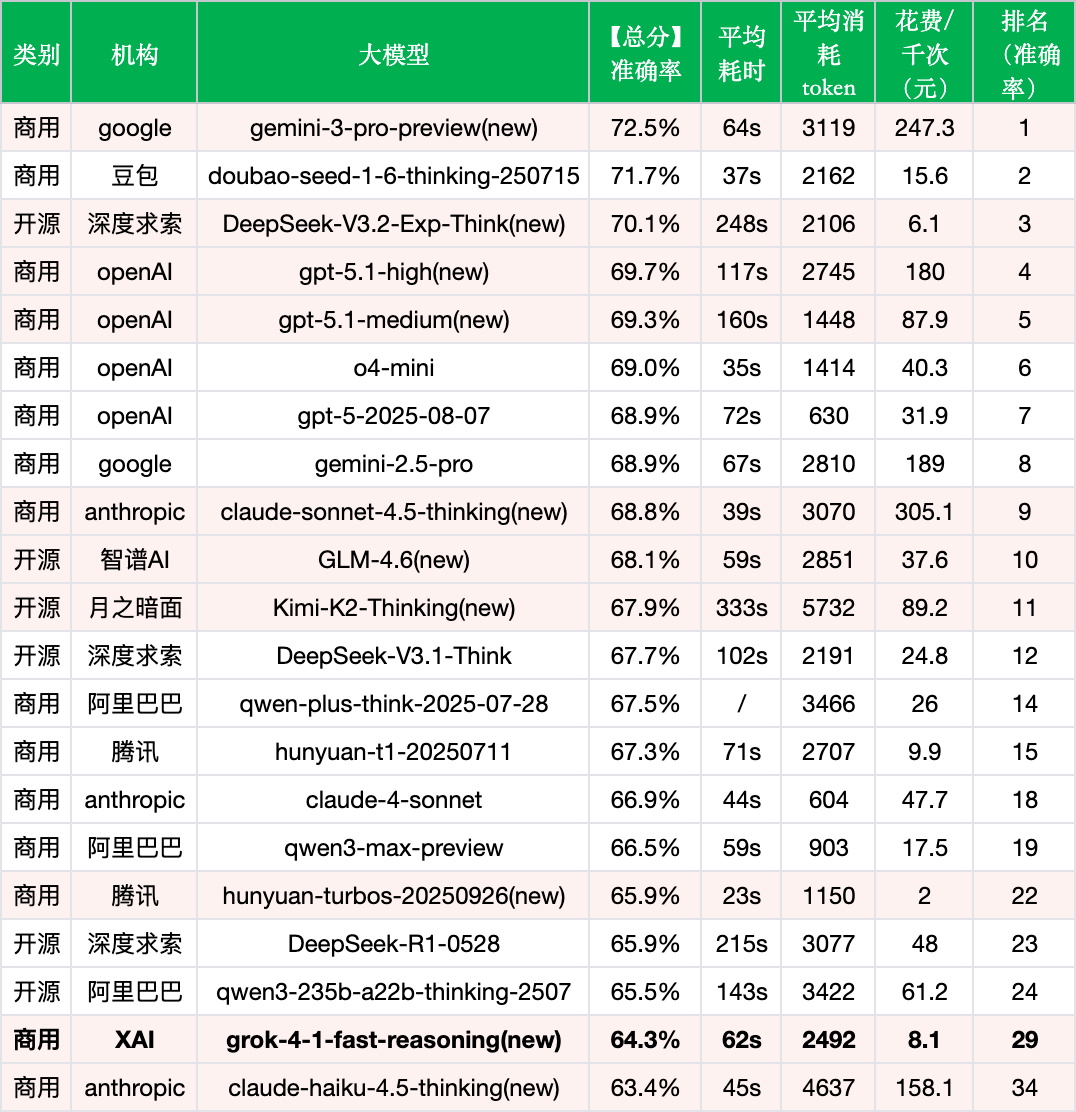
*数据来源:ReLE评测https://github.com/jeinlee1991/chinese-llm-benchmark
同成本档位对比分析
8元成本档表现中等:在相近成本区间(5-10元/千次),grok-4-1-fast-reasoning(8.1元)的64.3%准确率低于DeepSeek-V3.2-Exp-Think(6.1元,70.1%)和hunyuan-t1-20250711(9.9元,67.3%),在这个成本带中缺乏竞争力。
性价比劣势明显:相比超高性价比模型hunyuan-turbos-20250926(2元,65.9%),grok新版本在成本高出3倍的情况下,准确率反而低1.6个百分点,从总分情况来看,性价比差距悬殊。
新旧模型对比
新模型整体领先:从榜单看,新发布的模型如gemini-3-pro-preview(72.5%)、DeepSeek-V3.2-Exp-Think(70.1%)、gpt-5.1-medium(69.3%)等均位居前列,而grok-4-1-fast-reasoning(64.3%)在新模型中排名靠后。
新版本定位差异化:不同于追求极致准确率的新模型,grok-4-1-fast-reasoning选择了"速度+成本"的优化路线,牺牲部分准确率换取79%的速度提升和96%的成本下降,体现了差异化的产品策略。
开源VS闭源对比
grok在闭源阵营中定位尴尬:作为闭源商用模型,grok-4-1-fast-reasoning的64.3%准确率不仅低于主流闭源模型(gemini、doubao、openAI系列均在68%以上),甚至不敌部分开源模型(DeepSeek-V3.2、GLM-4.6、Kimi-K2均在67%以上),在闭源阵营中处于相对弱势地位。
速度与准确率的权衡:开源thinking模型普遍耗时较长(DeepSeek-V3.2-Exp-Think 248s、Kimi-K2-Thinking 333s、qwen3-235b-a22b-thinking-2507 143s),而grok以62s的中等耗时在速度和准确率之间找到了相对平衡的位置,但这一平衡点并未带来竞争优势——既不如速度型模型快(hunyuan-turbos-20250926 23s、o4-mini 35s),也不如准确率型模型准(前述模型均在65.5%以上)。
我们官网https://nonelinear.com/static/models.html已上线grok-4-1-fast-reasoning,欢迎对比体验。同时,非线智能API支持Api聚合以及Api中转,提供稳定的企业级服务。个人中心 https://nonelinear.com/static/balance.html 登录github账号,领50元体验金
大模型/agent评测技术交流:关注公众号,发送消息"进群"
