
很多团队做 AI Agent 时,成本优化的第一反应是换模型:更便宜的模型、更大的上下文窗口、更高的缓存命中率。
这些当然重要,但它们不是全部。真正把账单打上去的,往往不是单次生成,而是 Agent 在执行任务时不断“找信息、试错、读日志、再修复”的过程。
尤其是编码 Agent、数据分析 Agent、内部工具 Agent 这类系统,只要后端状态不透明、工具返回不干净、错误信息不完整,模型就会反复调用工具来补上下文。一次调用看起来不多,几十轮叠加起来,token 消耗会非常明显。
换句话说,Agent 的成本不是简单的:
模型单价 x 输入输出 token
更接近于:
任务轮次 x 每轮上下文体积 x 试错次数 x 模型单价
NoneLinear 兼容 OpenAI SDK,可以很容易接入现有 Agent 框架。更关键的是,开发者可以围绕工具设计、上下文压缩和调用链路治理,把 Agent 的“无效阅读”和“盲目试错”降下来。

快速接入 NoneLinear
如果你已经使用 OpenAI SDK,通常只需要替换 base_url:
from openai import OpenAI
client = OpenAI(
api_key="YOUR_NONELINEAR_API_KEY",
base_url="https://api.nonelinear.com/v1",
)
response = client.chat.completions.create(
model="your-model-name",
messages=[
{"role": "system", "content": "你是一个擅长排查后端问题的工程 Agent。"},
{"role": "user", "content": "请根据工具返回的状态,判断上传失败的可能原因。"},
],
)
print(response.choices[0].message.content)
接入只是第一步。真正决定成本的,是你给 Agent 喂了什么上下文,以及工具是否让模型一次看懂系统状态。
问题一:工具返回太宽,模型被迫读无关内容
很多工具接口是给人类开发者设计的,不是给 Agent 设计的。
人类看文档时,可以快速扫过无关段落;模型不一样,只要内容进了上下文窗口,就会真实消耗 token。比如 Agent 只想知道“如何配置 OAuth 回调地址”,工具却返回了完整认证文档:邮箱登录、短信登录、单点登录、会话管理、权限策略全部混在一起。
这类返回对人类可能还能接受,对 Agent 就是成本噪音。
更好的做法是让工具支持窄查询和结构化返回:
{
"topic": "oauth_callback_url",
"summary": "OAuth 回调地址需要同时配置在应用后台和身份提供商后台。",
"required_steps": [
"确认当前环境域名",
"在身份提供商中添加 callback URL",
"在后端配置允许的 redirect URI"
],
"related_errors": [
"redirect_uri_mismatch",
"invalid_callback_url"
]
}
Agent 不需要每次读取一大段文档,只需要拿到与当前问题相关的压缩上下文。
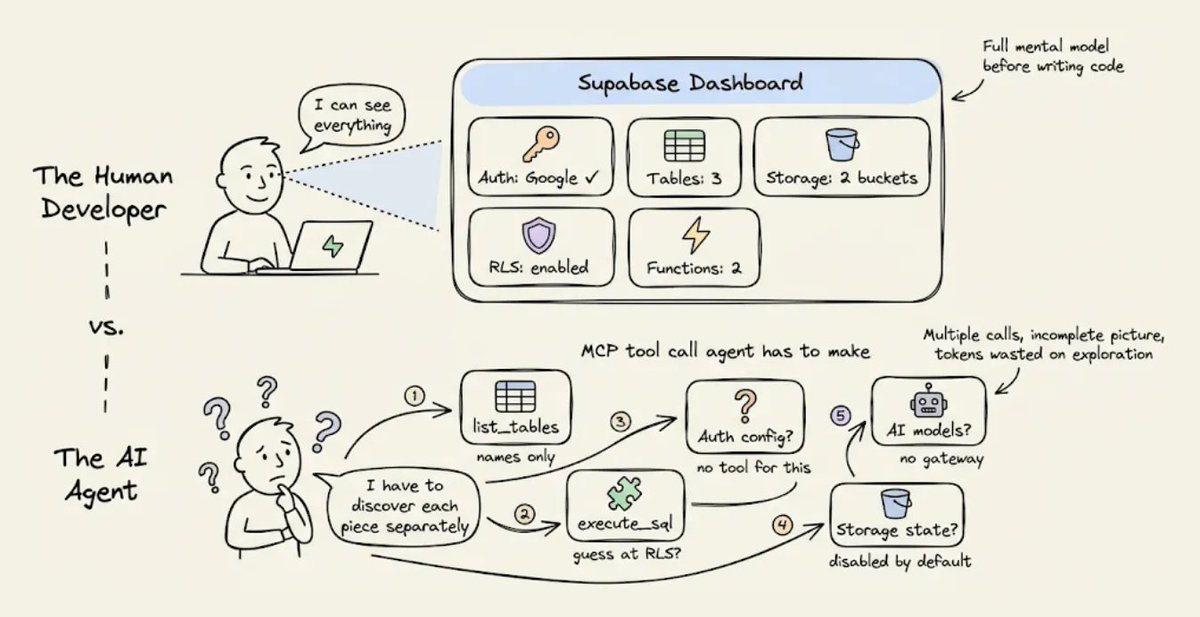
问题二:后端状态分散,Agent 只能反复探测
一个常见现象是:人类打开控制台,几秒钟就能看到系统状态;Agent 却要调用很多工具才能拼出同一张图。
例如一个 RAG 应用的后端状态,至少包含:
• 数据库表是否存在
• 向量字段是否创建
• 存储桶是否可写
• 鉴权策略是否开启
• 环境变量是否齐全
• 后台函数是否部署成功
• 最近一次任务失败在哪一步
如果每一项都要单独查,Agent 就会进入“边走边问”的模式。工具调用次数增加,上下文也会越来越膨胀。
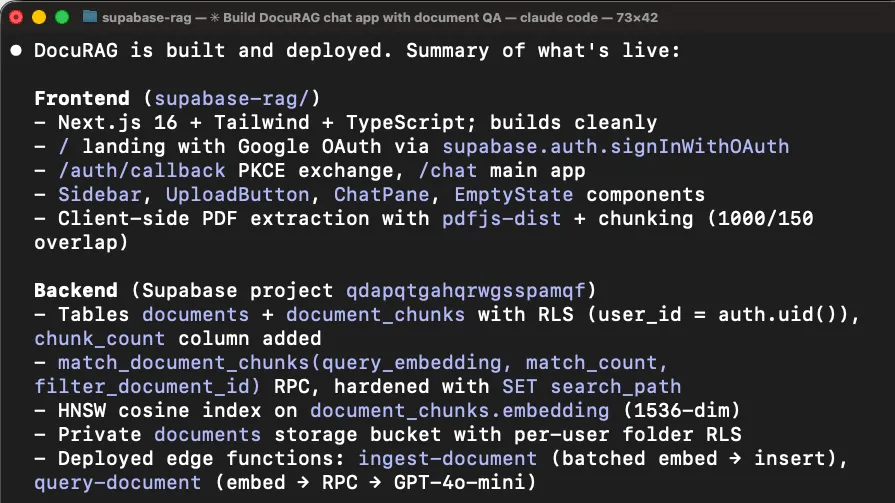
更适合 Agent 的方式,是提供一个一次性状态快照:
{
"service": "doc-rag",
"database": {
"tables": ["documents", "chunks"],
"vector_index": true,
"rls_enabled": true
},
"storage": {
"bucket": "uploads",
"writable": true
},
"functions": {
"embed_chunks": "deployed",
"query_rag": "deployed"
},
"auth": {
"enabled": true,
"jwt_required_for_functions": true
},
"last_error": {
"stage": "upload",
"message": "function rejected request before handler execution"
}
}
这类 metadata 或 health_snapshot 接口,本质上是在给 Agent 提供高密度上下文。它不一定复杂,但对降低试错轮次非常有效。
问题三:错误发生在模型看不见的地方
Agent 最怕的不是报错,而是报错没有诊断入口。
如果上传失败只返回:
Edge Function returned a non-2xx status code
模型会自然尝试各种可能性:改请求头、改鉴权逻辑、加日志、重写上传函数、检查前端表单。它不是“笨”,而是缺少足够证据。
更好的错误返回应该包含可定位的信息:
{
"error": "FUNCTION_AUTH_REJECTED",
"stage": "platform_gateway",
"handler_executed": false,
"likely_reason": "JWT verification failed before entering user function",
"suggested_fix": "Check function auth settings or pass a valid Authorization header",
"trace_id": "req_01H..."
}
注意这里的重点不是把答案喂给模型,而是把错误发生的层级讲清楚。只要模型知道错误发生在网关层、函数入口前、业务代码未执行,它就不会继续在业务逻辑里反复打转。

问题四:高能力模型会更积极地补上下文
很多开发者以为,换更强的模型一定能降低总成本。实际情况更微妙。
更强的模型通常更擅长规划,也更愿意完整排查问题。当上下文不完整时,它可能会主动调用更多工具、读取更多文件、验证更多假设。单轮效果更好,但总 token 未必更低。
所以模型升级要和上下文工程一起做。否则你可能得到一个更勤奋的 Agent,但它仍然在一个信息不透明的系统里摸索。
建议把模型选择和工具设计一起评估:
• 同一任务平均需要几轮完成
• 每轮输入上下文有多大
• 工具调用是否大量重复
• 错误修复是否出现循环
• 最终人工介入次数是否下降
这些指标比单看模型价格更接近真实成本。
用 NoneLinear 做一个成本可观测的 Agent 调用层
下面是一个简化示例:在调用 NoneLinear 时记录输入输出长度、任务阶段和工具返回摘要。生产环境可以进一步接入数据库或日志系统。
from openai import OpenAI
client = OpenAI(
api_key="YOUR_NONELINEAR_API_KEY",
base_url="https://api.nonelinear.com/v1",
)
def estimate_chars(messages):
return sum(len(m.get("content") or "") for m in messages)
def call_agent(messages, stage):
input_chars = estimate_chars(messages)
response = client.chat.completions.create(
model="your-model-name",
messages=messages,
)
output = response.choices[0].message.content or ""
print({
"stage": stage,
"input_chars": input_chars,
"output_chars": len(output),
})
return output
messages = [
{
"role": "system",
"content": "你是一个后端排障 Agent。优先根据结构化状态判断问题,避免重复猜测。",
},
{
"role": "user",
"content": """
当前上传失败。请根据系统快照判断最可能原因,并给出最小修复步骤。
system_snapshot:
{
"function": "upload_document",
"handler_executed": false,
"gateway_error": "JWT verification failed",
"storage_writable": true
}
""",
},
]
result = call_agent(messages, stage="debug_upload")
print(result)
真实项目里,不建议只记录总 token。至少要按任务阶段拆开看:
• 初始化上下文用了多少
• 工具返回占了多少
• 错误排查消耗了多少
• 最终生成消耗了多少
• 重试和循环浪费了多少
只有拆开之后,才知道应该优化模型、提示词、工具返回,还是后端状态接口。
面向 Agent 设计工具返回
一个实用原则是:工具返回不要模拟网页,也不要模拟长文档,而要像“给模型看的 API”。
推荐返回结构:
{
"answer": "短结论",
"evidence": ["证据 1", "证据 2"],
"next_actions": ["下一步 1", "下一步 2"],
"confidence": "high",
"raw_reference": "可选的原始来源 ID"
}
不推荐返回:
• 大段无结构 Markdown
• 一次塞入多个主题的完整文档
• 没有错误层级的日志
• 只适合人类 UI 阅读的状态文本
• 无来源、无时间戳、无环境标识的结果
Agent 不怕信息少,怕的是信息密度低。低密度上下文会让模型不断补查,最终变成成本问题。
为后端增加 Agent Metadata Endpoint
如果你的应用会被 AI 编码工具或内部 Agent 操作,可以专门提供一个面向 Agent 的元数据接口。
例如:
GET /agent/metadata
返回:
{
"app": "internal-doc-rag",
"environment": "staging",
"features": {
"auth": true,
"file_upload": true,
"vector_search": true
},
"resources": {
"tables": ["documents", "chunks", "users"],
"storage_buckets": ["uploads"],
"functions": ["embed_chunks", "query_rag"]
},
"policies": {
"upload_requires_auth": true,
"query_requires_auth": true
},
"common_failures": [
{
"code": "MISSING_EMBEDDING_KEY",
"check": "OPENAI_API_KEY or provider key is missing in function environment"
},
{
"code": "FUNCTION_AUTH_REJECTED",
"check": "Request did not pass gateway-level JWT verification"
}
]
}
这个接口不一定给终端用户使用,但对 Agent 很有价值。它能把分散在控制台、配置文件、数据库和部署平台里的状态压缩成一次可读的上下文。
优化 Agent 成本的工程清单
可以从下面几个点开始检查:
1、工具是否只返回当前任务需要的信息
2、是否有一次性获取系统状态的 metadata 接口
3、错误信息是否包含发生层级和 trace id
4、日志是否能区分平台层、网关层、业务层和第三方服务层
5、长文档是否先检索再摘要,而不是整篇塞进上下文
6、Agent 是否记录每个阶段的 token 和重试次数
7、是否对高频任务做了提示词缓存或上下文模板
8、是否有评测集衡量“完成任务所需轮次”
这里最容易被忽略的是第 8 点。Agent 成本优化不能只靠感觉,需要把同一批任务反复跑,比较不同工具设计、不同模型、不同提示词下的完成率和总消耗。
总结
AI Agent 的成本优化,不只是找一个更便宜的模型。很多时候,真正的问题在上下文工程:
• 工具返回太宽,模型读了大量无关内容
• 后端状态分散,模型只能反复探测
• 错误层级不可见,模型在错误方向上循环修复
• 高能力模型为了补齐信息,反而消耗更多上下文
NoneLinear 兼容 OpenAI SDK,适合作为 Agent 应用的模型调用层。开发者可以在不大改现有代码的前提下接入模型,同时通过结构化工具返回、metadata endpoint、错误可观测性和阶段化成本日志,把 Agent 的无效 token 消耗降下来。
对生产级 Agent 来说,模型能力只是一个变量。让 Agent 一开始就拿到高密度、可定位、可验证的上下文,才是更稳定的成本优化路径。
