
智谱AI近期开源了GLM-4.7-Flash新版本,官方定位为"Small but Powerful",宣称在编程能力和中文写作等场景表现出色。然而,我们的实测数据显示,相比GLM-4.5-Flash版本,GLM-4.7-Flash在多个关键指标上出现显著退步。我们对这两个版本进行了全面的对比评测,测试其在准确率、响应时间、token消耗和成本等关键指标上的表现差异。
GLM-4.7-Flash版本表现:
测试题数:约1.5万
总分(准确率):55.5%
平均耗时(每次调用):1238s
平均token(每次调用消耗的token):6690
平均花费(每千次调用的人民币花费):0
1、两版本对比
首先对比上个版本(GLM-4.5-Flash),数据如下:


*数据来源:ReLE评测https://github.com/jeinlee1991/chinese-llm-benchmark
*输出价格是"1元/M token "
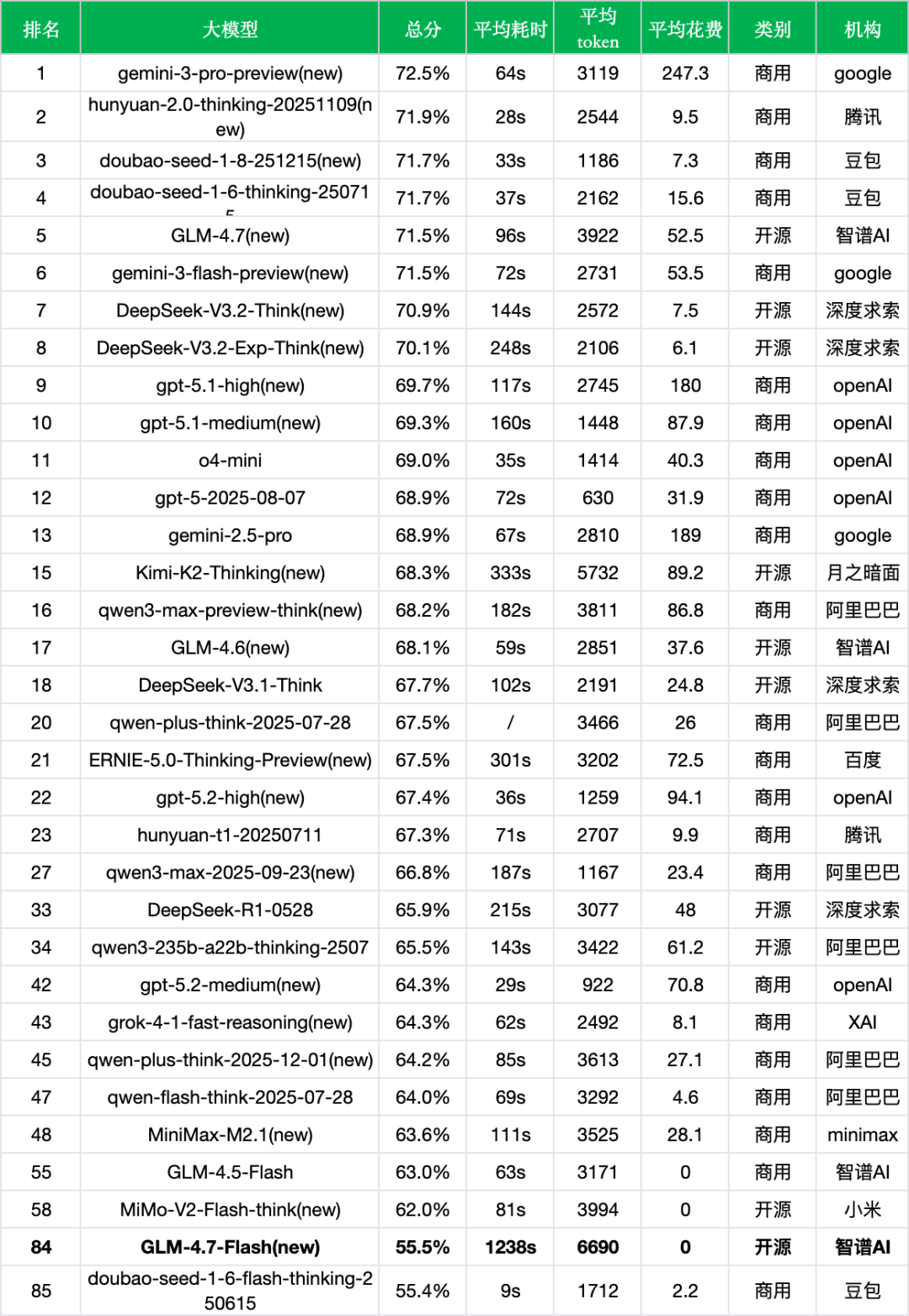
整体性能显著下滑:新版本准确率从63.0%大幅下降至55.5%,下降了7.5个百分点,排名从第55位跌落至第84位,出现了较大幅度的性能退步。
专业能力全面倒退:从细分领域来看,新版本在所有测试维度均出现明显下滑。其中"教育"领域从29.6%升至37.1%是唯一亮点,但"医疗与心理健康"从73.3%降至62.4%(-10.9%),"金融"从70.3%降至63.0%(-7.3%),"法律与行政公务"从72.7%降至58.7%(-14.0%),退步幅度均较为明显。
推理能力有所下滑:"推理与数学计算能力"从61.5%降至55.3%(-6.2%),在这一核心能力上的退步值得关注。
语言理解能力大幅下降:"语言与指令遵从"从65.5%降至48.9%(-16.6%),下降幅度最大,表明新版本在基础语言理解和指令遵循方面存在较大问题。
Agent能力小幅退步:"agent与工具调用"从64.1%降至62.7%(-1.4%),相对降幅较小,但仍低于前代版本。
Token消耗和响应时间异常:每次调用平均消耗的token从3171增加至6690,增幅达111%。更值得注意的是,平均响应时间从63s大幅增加到1238s(约20分钟),增幅近19倍,用户体验严重下降。
成本结构变化:虽然新版本输出价格设为0元/M token(开源免费调用),相比GLM-4.5-Flash实现了成本降低,但考虑到性能的全面下滑,这一"免费"优势的实际价值大打折扣。
2、对比其他新模型
在当前主流大模型竞争格局中,GLM-4.7-Flash表现如何?我们从同成本档位、新旧模型对比、开源VS闭源三个维度进行分析:
*数据来源:ReLE评测https://github.com/jeinlee1991/chinese-llm-benchmark
同成本档位对比
免费模型中垫底:GLM-4.7-Flash作为免费开源模型,与同样免费的MiMo-V2-Flash-think(62.0%)相比,准确率处于相近或更低水平。但在响应时间上,GLM-4.7-Flash的1238s远逊于MiMo-V2-Flash-think的81s。
性价比优势不明显:虽然免费,但考虑到超长的响应时间和较低的准确率,在实际应用中可能反而增加开发调试成本。
新旧模型对比
智谱AI产品线表现分化:同厂商的GLM-4.7以71.5%准确率排名第5,展现了较强的竞争力。但GLM-4.7-Flash作为轻量版本,与主力模型的差距达到16个百分点,产品定位存在较大落差。
新模型整体水平提升:当前榜单前列的新模型如gemini-3-pro-preview(72.5%)、hunyuan-2.0-thinking-20251109(71.9%)、doubao-seed-1-8-251215(71.7%)均展现了较高水准,GLM-4.7-Flash的55.5%与这些新模型存在明显差距。
开源VS闭源对比
开源模型中表现靠后:与同为开源的GLM-4.7(new)(71.5%)、DeepSeek-V3.2-Think(70.9%)、DeepSeek-V3.2-Exp-Think(70.1%)相比,GLM-4.7-Flash的55.5%处于明显劣势。
轻量模型竞争激烈:在追求"small but powerful"的定位上,GLM-4.7-Flash需要面对MiMo-V2-Flash-think(62.0%)、qwen-flash-think-2025-07-28(64.0%)等同类产品的竞争,目前未能展现出明显优势。
闭源模型普遍领先:排名前列的闭源模型如gemini-3-pro-preview(72.5%,商用)、hunyuan-2.0-thinking-20251109(71.9%,商用)等,在准确率上普遍高于GLM-4.7-Flash 15个百分点以上。
注意,智谱官方指出,GLM-4.7-Flash(300亿参数,30亿激活)与GLM-4.5-Flash(1060亿参数,120亿激活)并非同一产品线的迭代版本,两者参数规模相差约3.5倍。本文对比仅供参考,需注意两者定位差异。另外,我们非线智能官网https://nonelinear.com/static/models.html已上线GLM-4.7-Flash,欢迎对比体验。同时,非线智能API支持Api聚合以及Api中转,提供稳定的企业级服务。个人中心 https://nonelinear.com/static/balance.html 登录github账号,领50元体验金
大模型/agent评测技术交流:关注公众号,发送消息"进群"
