
很多团队在做 AI Agent 时,第一反应是写更长的 system prompt。把规则、案例、流程、约束、代码片段都塞进去,希望模型每次都能按固定方式工作。
这条路很快会遇到上限:
• prompt 越写越长,维护成本越来越高
• 不同任务共享同一段大上下文,token 浪费严重
• 规则散落在聊天记录里,很难版本管理
• 团队成员各写各的提示词,产出风格不一致
• 模型需要重复学习同一套流程
更工程化的做法,是把某类任务需要的知识、流程、脚本和素材打包成一个可复用的能力单元。这里可以把它称为 Skill。
Skill 不是一句提示词,也不只是一个 Markdown 文件。更准确地说,它是一组围绕特定任务组织起来的文件夹资产:说明文档、示例、脚本、模板、参考数据、配置和可选 hooks 都可以放进去。

NoneLinear 兼容 OpenAI SDK,适合作为 Agent 应用的模型调用层。开发者可以在自己的 Agent 框架中加入 Skill 机制,让模型在需要时加载对应能力,而不是每次都带着一整套通用提示词运行。
快速接入 NoneLinear
如果你已经在项目里使用 OpenAI SDK,接入 NoneLinear 通常只需要替换 base_url:
from openai import OpenAI
client = OpenAI(
api_key="YOUR_NONELINEAR_API_KEY",
base_url="https://api.nonelinear.com/v1",
)
response = client.chat.completions.create(
model="your-model-name",
messages=[
{"role": "system", "content": "你是一个支持 Skills 的 AI Agent。"},
{"role": "user", "content": "请使用代码审查 Skill 检查这个 PR 的风险点。"},
],
)
print(response.choices[0].message.content)
真正的关键不在这段调用,而在于:如何把 Skill 设计成模型愿意用、用得准、还不会浪费上下文的结构。
Skill 应该是什么结构
一个实用的 Skill 可以按文件夹组织:
skills/
code-review/
SKILL.md
examples/
good-review.md
bad-review.md
scripts/
collect_diff.sh
run_tests.sh
templates/
review-output.md
references/
severity-guide.md
其中 SKILL.md 是入口文件,用来告诉 Agent:
• 这个 Skill 适合什么任务
• 什么时候应该触发
• 优先读取哪些文件
• 可以调用哪些脚本
• 输出格式是什么
• 哪些错误需要避免
示例:
# Code Review Skill
## When to use
Use this skill when the user asks for review, PR risk analysis, regression detection, or missing test coverage.
## Workflow
1. Inspect the changed files.
2. Identify behavioral bugs before style issues.
3. Report findings with file and line references.
4. Mention test gaps only after concrete findings.
## Output
Start with findings ordered by severity. If no issues are found, say so clearly and mention residual risk.
这比把所有规则硬塞进 system prompt 更清晰,也更容易在团队中共享。
设计 Skill 的核心原则:渐进披露
Skill 最大的价值之一,是让 Agent 只在需要时读取必要信息。
不要把全部规则、案例、脚本说明、长文档都写进 SKILL.md。入口文件应该短,负责路由;细节应该放到子目录里,按需加载。
推荐结构是:
SKILL.md # 触发条件、任务流程、输出约束
references/ # 较长的领域资料
examples/ # 好坏样例
scripts/ # 可执行工具
assets/ # 模板、图片、字体、数据文件
这样做有两个好处:
1、Agent 不需要每次读取整套资料,token 更可控 2、Skill 可以持续扩展,不会把入口文件变成新的超长 prompt
一个好的 SKILL.md 应该像索引页,而不是百科全书。

Skill 描述要写给模型看
很多人写 Skill 描述时,会写成给人看的 README,例如:
这是一个用于数据分析的 Skill。
这类描述太泛,模型很难判断何时该用它。
更好的写法是把触发场景说清楚:
Use this skill when the user asks to inspect CSV files, summarize tabular data, detect outliers, generate charts, or explain trends from datasets.
触发描述要包含任务动词和对象,例如:
• inspect CSV files
• review pull requests
• convert notes into articles
• generate UI components
• extract action items
• debug API errors
模型不是靠 Skill 名称猜用途,而是靠描述判断是否相关。描述越具体,误触发和漏触发越少。
9 类最适合做成 Skill 的场景
不是所有提示词都值得做成 Skill。更适合 Skill 化的任务,通常有固定流程、重复出现、需要外部文件或团队标准。
下面是开发团队最常见的 9 类高价值场景。
1. 文档处理 Skill
适合处理 PDF、Word、Markdown、网页摘录、会议纪要和内部知识库。
可以包含:
• 摘要模板
• 结构化抽取规则
• 术语表
• 输出格式示例
• 文档分块脚本
典型任务:
• 把会议记录转成待办清单
• 从技术文档中提取 API 参数
• 把长文档压缩成决策摘要
• 将 Markdown 文章改写成博客稿
2. 代码审查 Skill
适合团队统一 PR review 标准。
可以包含:
• 严重程度分级规则
• 常见 bug checklist
• 本项目测试命令
• 文件引用格式
• 禁止只给风格建议的约束
典型任务:
• 找行为回归
• 检查边界条件
• 发现缺失测试
• 识别安全风险
• 输出可直接贴到 PR 的 review
3. 数据分析 Skill
适合 CSV、数据库导出、日志、实验结果、评测报告等分析任务。
可以包含:
• 数据清洗脚本
• 图表生成模板
• 指标定义
• 异常值判断规则
• 分析报告格式
典型任务:
• 对模型评测结果做汇总
• 分析用户增长数据
• 找出异常样本
• 把日志转成可读结论
• 生成图表和洞察
4. UI 生成 Skill
适合需要稳定设计风格的前端项目。
可以包含:
• 设计系统规范
• 组件使用规则
• 颜色和间距约束
• 禁用模式
• 页面示例
典型任务:
• 生成 React 组件
• 改造仪表盘页面
• 按品牌风格输出落地页
• 为管理后台补齐交互状态
这类 Skill 特别适合团队统一视觉标准,避免每次生成出来的 UI 都像不同项目。
5. Agent 工具使用 Skill
适合告诉 Agent 如何正确调用内部工具。
可以包含:
• 工具调用顺序
• 参数说明
• 错误处理方式
• 重试策略
• 不应调用工具的情况
典型任务:
• 调用内部搜索
• 查询订单状态
• 分析服务健康度
• 执行部署前检查
这类 Skill 的价值在于减少“盲目调用工具”。Agent 知道什么时候该查、查什么、查不到怎么办,整体成本会明显下降。
6. 内容生产 Skill
适合团队做博客、社媒、产品更新、案例文章、教程和邮件。
可以包含:
• 品牌语气
• 标题风格
• 文章结构
• 禁用词
• SEO 要求
• 样例文章
典型任务:
• 把技术调研改写成博客
• 把 release note 改成开发者公告
• 把英文资料转成中文文章
• 根据产品能力生成场景案例
如果团队长期产出内容,这类 Skill 能显著降低风格漂移。
7. 测试与评测 Skill
适合 LLM 应用、Agent、RAG、模型 API 和业务系统的质量验证。
可以包含:
• 测试命令
• 评测指标说明
• 失败样本分类
• 报告模板
• 回归测试流程
典型任务:
• 为新功能补测试
• 生成评测数据集
• 对比不同模型结果
• 判断提示词修改是否导致回归
• 汇总 benchmark 报告
这类 Skill 可以把“凭感觉看效果”变成可重复的工程流程。
8. 项目知识 Skill
适合把某个代码库、产品线或团队流程的知识沉淀下来。
可以包含:
• 架构说明
• 目录约定
• 常用命令
• 发布流程
• 关键业务概念
• 历史决策记录
典型任务:
• 新人快速理解项目
• Agent 修改代码前读取项目约束
• 生成符合团队规范的实现
• 避免重复问同样的上下文
项目知识 Skill 很适合和仓库一起版本管理。
9. 个人工作流 Skill
适合个人长期复用的工作方式。
可以包含:
• 笔记整理格式
• 任务拆解方式
• 写作偏好
• 日报周报模板
• 常用脚本
典型任务:
• 整理 Obsidian 笔记
• 生成周报
• 把会议语音转成行动项
• 根据个人风格改写文章
这类 Skill 不一定适合全团队共享,但非常适合个人知识管理和个人自动化。
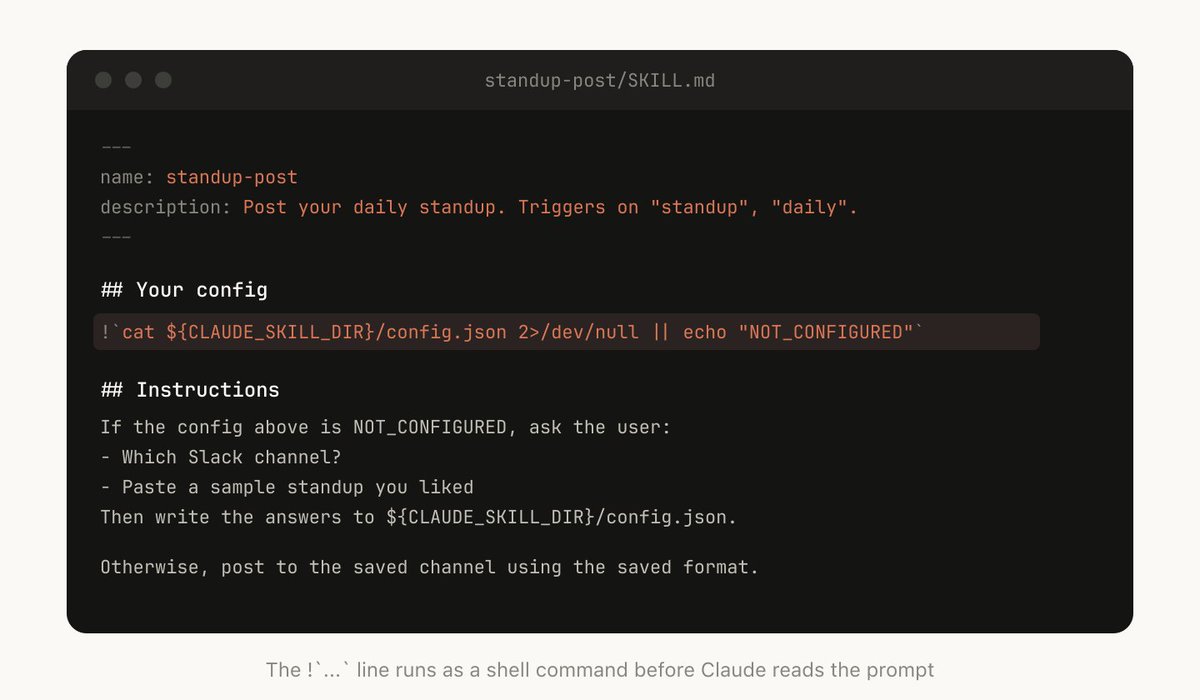
Skill 不只是文档,也可以包含脚本
如果某个步骤可以稳定用程序完成,就不要让模型每次都“想一遍”。
例如数据分析 Skill 可以包含:
scripts/
profile_csv.py
detect_outliers.py
render_chart.py
代码审查 Skill 可以包含:
scripts/
changed_files.sh
run_unit_tests.sh
summarize_diff.py
文档处理 Skill 可以包含:
scripts/
extract_pdf_text.py
split_markdown.py
normalize_frontmatter.py
模型擅长判断、归纳和生成,但不应该承担所有机械步骤。脚本能让 Skill 更稳定,也能减少 token 消耗。
用持久数据减少重复上下文
有些知识不应该每次都由用户重新提供。
例如:
• 品牌语气
• 产品术语
• 常用 API 参数
• 团队输出模板
• 项目目录约定
• 常见错误码
这些内容可以放在 Skill 的 references/ 或 templates/ 中。Agent 在需要时读取,而不是每次都让用户复制一遍。
示例:
skills/
nonelinear-blog-writer/
SKILL.md
references/
brand-voice.md
api-positioning.md
forbidden-phrases.md
templates/
scenario-article.md
这会让输出更一致,也更适合多人协作。

Hooks 适合做轻量自动化
有些动作不需要模型参与,适合放到 hooks 或脚本里自动执行。
例如:
• 生成文章后自动检查是否包含敏感来源
• 保存代码前自动格式化
• 运行测试前自动收集变更文件
• 输出报告前自动统计 token 或耗时
但 hooks 不宜过多。太多自动动作会让系统行为变得难以解释,也容易增加调试成本。
推荐原则是:只有稳定、低风险、可重复的步骤才放进 hooks;需要判断和取舍的步骤交给 Agent。
Skill 可以组合,但要避免互相打架
真实任务经常需要多个 Skill 协作。
例如生成一篇开发者博客,可能会用到:
• 项目知识 Skill:读取产品定位和 API 接入方式
• 内容生产 Skill:确定文章结构和语气
• 代码示例 Skill:生成 SDK 示例
• 审校 Skill:检查事实、格式和禁用词
组合使用时,最重要的是边界清晰。每个 Skill 只负责自己的阶段,不要多个 Skill 同时规定最终输出风格,否则模型容易收到冲突指令。
一个可行的链路是:
收集上下文 -> 生成大纲 -> 写正文 -> 补代码示例 -> 审校 -> 输出最终稿
每一步调用不同 Skill,比一次性加载所有 Skill 更稳。
Skill 应该能被分发和版本管理
如果 Skill 只是一个本地提示词片段,很难团队化。
更好的方式是把 Skill 当作项目资产:
• 放进 Git 仓库
• 使用版本号
• 写清依赖
• 提供示例输入输出
• 记录更新日志
• 标注适用项目和不适用场景
例如:
skills/
code-review/
SKILL.md
CHANGELOG.md
examples/
scripts/
当团队成员都使用同一套 Skill,Agent 的输出就会更一致。后续要优化,也能像改代码一样做 review。
如何判断一个 Skill 做得好不好
Skill 不是写完就结束。它应该像代码一样被评估。
可以从这些指标开始:
• 任务完成率是否提升
• 平均对话轮次是否下降
• 用户补充说明次数是否减少
• 输出格式是否更稳定
• 人工修改量是否下降
• token 消耗是否下降
• 误触发率是否可接受
• 是否能跨团队成员复用
对高频任务,建议准备一组固定测试样例。每次修改 Skill 后,用同一批任务跑一遍,看结果是否更好。
这和 LLM 应用评测是同一套思路:不要只看“感觉更聪明”,要看重复任务上的稳定性。
在 NoneLinear 中加载 Skill 的一种实现方式
下面是一个简化示例:根据用户请求选择 Skill,读取入口文件,再把必要上下文交给 NoneLinear。
from pathlib import Path
from openai import OpenAI
client = OpenAI(
api_key="YOUR_NONELINEAR_API_KEY",
base_url="https://api.nonelinear.com/v1",
)
def load_skill(name: str) -> str:
skill_path = Path("skills") / name / "SKILL.md"
return skill_path.read_text(encoding="utf-8")
def run_with_skill(skill_name: str, user_task: str):
skill = load_skill(skill_name)
messages = [
{
"role": "system",
"content": (
"You are an AI Agent. Follow the loaded Skill when it is relevant. "
"Do not invent files or project facts that were not provided."
),
},
{
"role": "user",
"content": f"Loaded Skill:\n\n{skill}\n\nUser task:\n\n{user_task}",
},
]
response = client.chat.completions.create(
model="your-model-name",
messages=messages,
)
return response.choices[0].message.content
print(run_with_skill(
"code-review",
"请审查这个 PR,重点关注行为回归和缺失测试。"
))
生产环境可以进一步加入:
• Skill 检索
• 权限控制
• 文件白名单
• 子文件按需读取
• 脚本执行沙箱
• 版本锁定
• 调用日志和评测集
不要一开始就做复杂平台。先让一个高频任务 Skill 跑起来,再逐步扩展。
常见误区
误区一:把 Skill 写成超长 prompt
这会失去 Skill 的意义。入口应该短,细节按需读取。
误区二:Skill 描述太泛
“用于提升效率”这类描述对模型没有帮助。要写清楚任务、对象和触发条件。
误区三:所有步骤都交给模型
稳定的机械步骤应该脚本化。模型负责判断,脚本负责执行。
误区四:没有输出模板
没有模板,Agent 每次都可能换一种格式。高频团队任务一定要规定输出结构。
误区五:不做评测
Skill 也是工程资产。没有测试样例,就很难知道修改到底是优化还是退化。
总结
Skill 是让 AI Agent 从“会聊天”走向“会稳定做事”的关键抽象。
它把某类任务所需的流程、知识、示例、脚本和模板沉淀为可复用的文件夹能力包。相比不断加长 system prompt,Skill 更适合长期维护、团队共享、版本管理和按需加载。
对开发者来说,可以从 9 类场景入手:
• 文档处理
• 代码审查
• 数据分析
• UI 生成
• Agent 工具使用
