
阿里巴巴近期发布了qwen3-max-preview-think新版本,这是在qwen3-max-preview基础上引入thinking思维链模式的升级版本。我们对这两个版本进行了全面的对比评测,测试其在准确率、响应时间、token消耗和成本等关键指标上的表现差异。
qwen3-max-preview-think版本表现:
测试题数:约1.5万
总分(准确率):68.2%
平均耗时(每次调用):182s
平均token(每次调用消耗的token):3811
平均花费(每千次调用的人民币花费):86.8
1、版本对比
首先对比非思考版本(qwen3-max-preview),数据如下:


*数据来源:ReLE评测https://github.com/jeinlee1991/chinese-llm-benchmark
*输出价格是"1元/M token "
整体性能温和提升:新版本准确率从66.5%提升至68.2%,增长了1.7个百分点,排名从第29位上升至第16位,显示出thinking模式对整体准确率的正向作用。
Agent能力实现突破:从细分领域来看,“agent与工具调用”能力从45.8%大幅跃升至68.5%,增幅高达22.7个百分点,这是所有能力维度中最显著的提升,表明深度推理过程显著增强了复杂工具调用的决策质量。
语言理解能力大幅下降:“语言与指令遵从”从71.9%降至58.1%,下降了13.8个百分点,成为最大的负面变化。这一现象可能源于thinking模式的冗长推理过程干扰了对简洁指令的直接执行。
专业领域表现高度分化:“推理与数学计算”从71.0%提升至75.0%,增长4.0个百分点,验证了thinking模式在逻辑推理上的优势。然而,“教育”领域从54.2%降至46.3%,下降7.9个百分点;“金融”从85.1%降至80.4%,下降4.7个百分点;“法律与行政公务”从77.0%降至73.2%,下降3.8个百分点;“医疗与心理健康”从82.8%降至82.0%,下降0.8个百分点。这种分化表明thinking模式更适合需要深度推理的场景,而在知识密集型领域可能引入不必要的推理开销。
Token消耗呈爆炸式增长:每次调用平均消耗的token从903激增至3811,增幅达322%,这是thinking模式生成大量中间推理步骤的直接结果。
调用成本急剧攀升:每千次调用的费用从17.5元激增至86.8元,增幅高达396%,成本增长幅度远超准确率提升幅度,使得该模型在成本敏感场景中的适用性受到限制。
响应时间显著延长:新版本的平均耗时为182s,相比非思考版本的59s慢了约208%,这是thinking模式进行逐步推理所需的时间代价,对实时性要求高的应用构成制约。
2、对比其他模型
在当前主流大模型竞争格局中,qwen3-max-preview-think表现如何?我们从三个维度进行横向对比分析(本评测侧重中文场景,模型在其他语言和专业领域的表现可能有所不同):
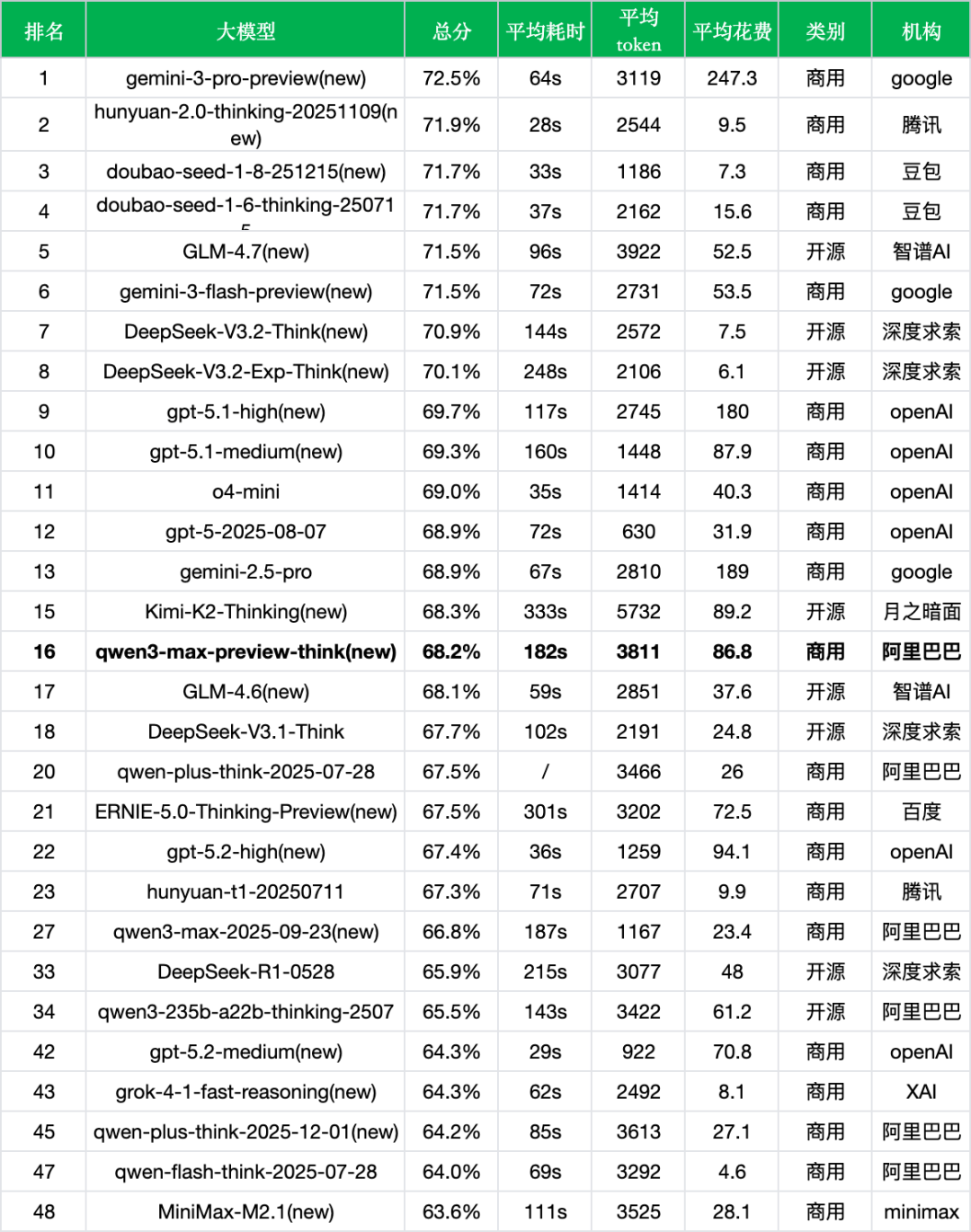
*数据来源:ReLE评测https://github.com/jeinlee1991/chinese-llm-benchmark
同成本档位对比:
成本处于较高水平:86.8元/千次的成本在对比模型中位于高位区间,仅低于Kimi-K2-Thinking(89.2元)、gpt-5.1-medium(87.9元)和gpt-5.2-high(94.1元)等。
同成本区间表现平平:在80-90元成本档位中,准确率68.2%与Kimi-K2-Thinking(68.3%)基本持平,但略低于gpt-5.1-medium(69.3%),在该价位段并未展现明显优势。
成本效率存在差距:对比成本更低的thinking模型,ERNIE-5.0-Thinking-Preview(67.5%,72.5元)准确率仅低0.7个百分点,成本却低16.5%;hunyuan-2.0-thinking-20251109(71.9%,9.5元)准确率反而高3.7个百分点,成本却仅为新版本的11%,凸显出成本控制上的明显劣势。
新旧模型对比:
Thinking模式的权衡本质:相比非思考版本qwen3-max-preview(66.5%,排名29),thinking版本以准确率提升1.7个百分点为代价,换取了成本增加396%和响应时间延长208%的结果,这一权衡是否值得高度依赖具体应用场景需求。
能力分化的启示:agent能力的飞跃(+22.7个百分点)与语言理解的滑坡(-13.8个百分点)形成鲜明对比,揭示了thinking模式并非万能方案,而是在特定能力维度上做出了明确取舍。
产品定位清晰化:两个版本在性能特征上的巨大差异为不同应用场景提供了明确选择:需要复杂推理和工具调用的场景选thinking版本,追求效率和简洁响应的场景选基非思考版本。
开源VS闭源对比:
闭源阵营中游表现:作为商用闭源模型,qwen3-max-preview-think(68.2%)在闭源阵营中处于中等位置,明显落后于榜首的gemini-3-pro-preview(72.5%)和hunyuan-2.0-thinking-20251109(71.9%)。
开源thinking模型竞争力强劲:开源阵营在thinking模式上展现出色表现。DeepSeek-V3.2-Think(70.9%,7.5元)准确率高2.7个百分点,成本却仅为9%;GLM-4.6(68.1%,37.6元)准确率接近,成本仅为43%;DeepSeek-V3.1-Think(67.7%,24.8元)和qwen3-235b-a22b-thinking-2507(65.5%,61.2元)等模型在准确率相近时成本优势明显。
开源模型的迭代速度优势:开源thinking模型的快速优化表明,仅依靠thinking模式提升准确率已不足以建立持久竞争优势,闭源商用模型需要在响应速度、成本控制和特定场景能力上寻找突破点。
差异化能力的重要性:在开源模型全面崛起的背景下,新版本在agent能力上的显著提升(68.5%)提供了一个可能的差异化方向,但需要进一步降低成本才能形成真正的竞争力。
我们官网https://nonelinear.com/static/models.html已上线qwen3-max-preview-think,欢迎对比体验。同时,非线智能API支持Api聚合以及Api中转,提供稳定的企业级服务。个人中心 https://nonelinear.com/static/balance.html 登录github账号,领50元体验金
大模型/agent评测技术交流:关注公众号,发送消息"进群"
