

近期,智谱和阿里放出了新模型——GLM-5V-Turbo 和 qwen3.6-plus。一个主打「视觉编程」,一个号称「国产编程最强」。
编程能力都很亮眼,但表格识别呢?我们第一时间将它们纳入了 NoneLinear 表格图片识别排行榜。
以下是最新完整排行榜:
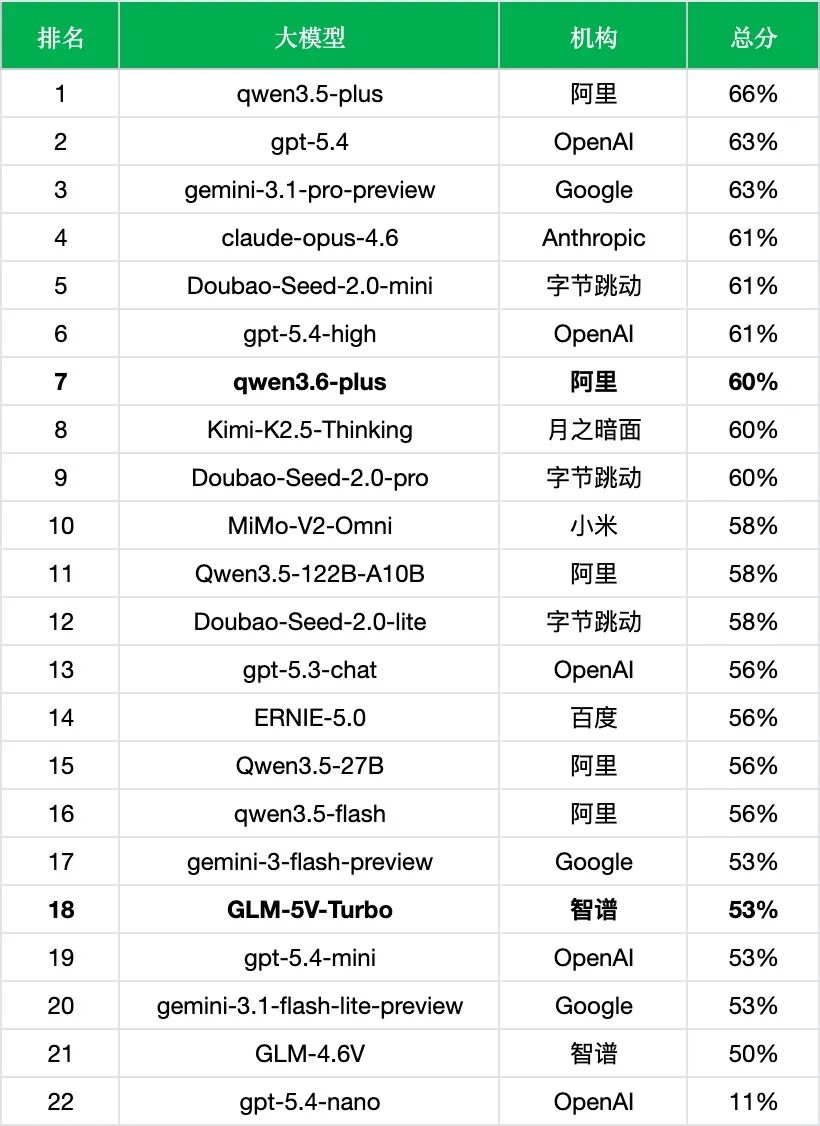
* 评测标准:表格结构与内容须与原图完全一致,任一不符即判错。
下面逐个拆解两款新模型的表格识别表现。
Qwen3.6-Plus 阿里
qwen3.6-plus 是阿里发布的新一代大语言模型,被官方称为「当下编程能力最强的国产模型」。在 SWE-bench Verified、Terminal-Bench 2.0、Claw-Eval 等编程与智能体评测中,以更小的参数量超越了 GLM-5、Kimi-K2.5 等 2~3 倍体量的模型。模型具备原生多模态理解与推理能力,并深度适配 OpenClaw、Claude Code 等主流 Agent 框架。
准确率 60%,排名第 7
相比上一代 qwen3.5-plus(66%,排名第 1),表格识别准确率反而下降了 6 个百分点,从榜首滑落到第 7 名。与 Kimi-K2.5-Thinking、Doubao-Seed-2.0-pro 同处 60% 梯队。编程能力的代际跃升并未带来表格识别能力的同步提升。


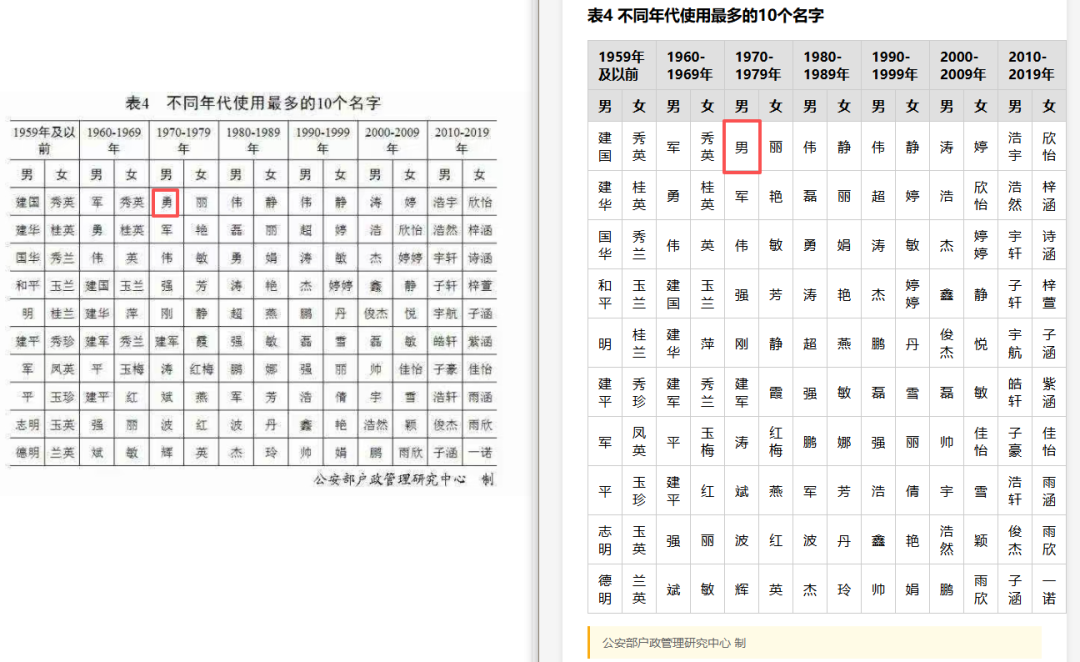
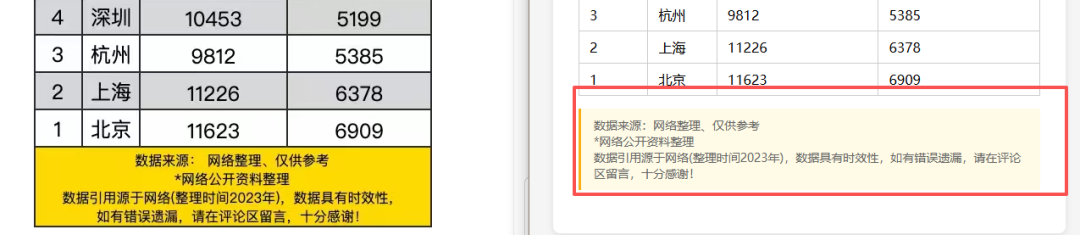
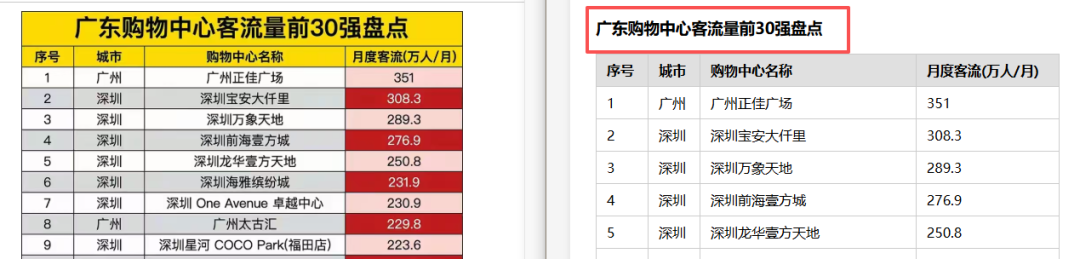
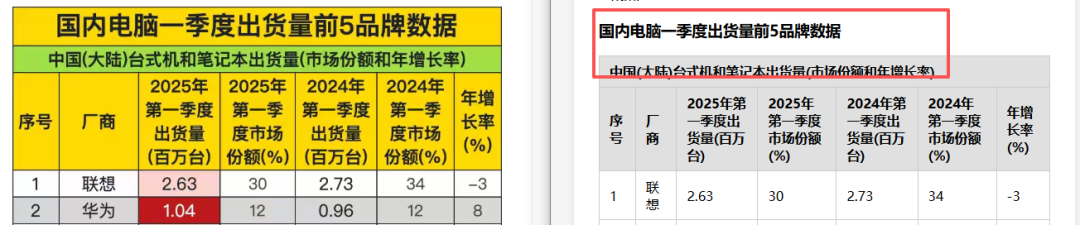

主要短板
表格内容和数值识别错误是最突出的问题——个别数字、文字内容出错,看起来结构对了但数据失真。表格结构识别也时有错乱。表头方面,内容识别错误、缺失、甚至将附注内容错误地识别为表格正文内容。水印区域的处理同样不理想,有时直接将水印文字识别出来混入数据。此外,标题内容偶尔被省略。
小结:qwen3.6-plus 的编程能力确实较 3.5 有了显著飞跃,但表格识别不升反降。这再次印证了一个规律——模型的迭代升级并不意味着所有维度同步进步,编程优化可能挤占了其他能力的训练资源。
GLM-5V-Turbo 智谱
GLM-5V-Turbo 是智谱发布的多模态 Coding 基座模型,定位「面向视觉编程」。该模型从预训练阶段就深度融合视觉与文本能力,采用自研新一代 CogViT 视觉编码器,能直接看懂设计稿、截图、网页界面并生成完整可运行代码。
准确率 53%,排名第 18
与 gpt-5.4-mini、gemini-3-flash-preview、gemini-3.1-flash-lite-preview 同处 53% 梯队。相比同门前辈 GLM-4.6V(50%),仅提升了 3 个百分点。Design2Code 得分 94.8 的「视觉编程之王」,在表格识别上却排名倒数第 5——能看懂设计稿不代表能看懂统计报表。

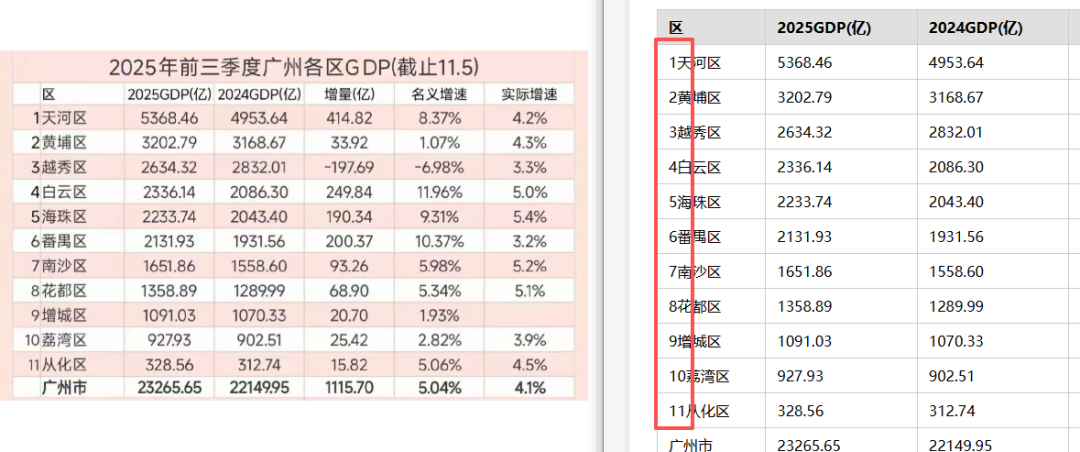

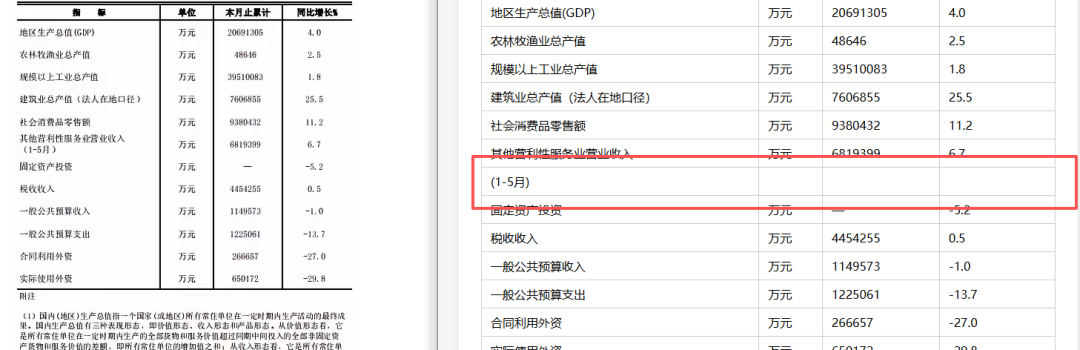



主要短板
水印导致内容缺失是最明显的问题。表头结构识别频繁出错,分不清表头内容和标题的边界。多层表头结构识别失败,嵌套列头还原崩坏。表格内容偶有文字、数字识别错误。整体错误模式与 GLM-4.6V 一脉相承,视觉能力的升级集中在了编程场景,对表格还原帮助有限。
小结:GLM-5V-Turbo 在设计稿转代码上确实是行业领先,但表格识别只有 53%。「看懂 UI 布局生成代码」和「忠实还原表格数据」是两种截然不同的视觉理解能力——前者需要理解布局逻辑,后者需要逐字逐行的精确感知。
两款新模型告诉我们什么?
新一代不一定比老一代强
qwen3.6-plus 编程能力超越了 qwen3.5-plus,但表格识别反而从 66% 降到 60%。GLM-5V-Turbo 视觉编程碾压前辈,但表格识别只比 GLM-4.6V 好了 3 个百分点。模型的版本迭代有时是「有所为有所不为」——编程/Agent 方向的重点投入,可能意味着其他能力的训练优先级下调。
「看懂图片」≠「还原表格」
GLM-5V-Turbo 的 Design2Code 得分高达 94.8,说明它对 UI 布局、配色、组件层级的理解极为出色。但表格识别要求的是另一种能力:逐行逐列的精确文本提取 + 严格的结构还原 + 零幻觉零改写。两者之间的鸿沟比想象中大得多。
─── NONELINEAR 模型超市 ───
两款新模型上线当天即完成适配,通过 NoneLinear 模型超市(https://nonelinear.com/static/models.html)即可一键调用——一套代码、统一接口、零适配成本。
# 一套代码,调用任意多模态模型
import base64
from openai import OpenAI
def file_to_base64(file_path):
with open(file_path, "rb") as f:
return base64.b64encode(f.read()).decode("utf-8")
# 1. 设置 NoneLinear API
API_KEY = "your-api-key"
BASE_URL = "https://api.nonelinear.com/v1"
client = OpenAI(api_key=API_KEY, base_url=BASE_URL)
# 2. 准备图片数据
image_path = "sample_table.jpg"
base64_image = file_to_base64(image_path)
data_url = f"data:image/jpeg;base64,{base64_image}"
# 3. 调用模型(换 model 名即可切换)
response = client.chat.completions.create(
model="qwen3.6-plus",
messages=[{
"role": "user",
"content": [
{"type": "image_url",
"image_url": {"url": data_url}},
{"type": "text",
"text": "请识别图片中的表格内容,
并以 HTML 格式输出。"}
],
}]
)
print(response.choices[0].message.content)大模型/agent评测技术交流:关注公众号,发送消息"进群"。同时,非线智能API支持Api聚合以及Api中转,提供稳定的企业级服务。个人中心 https://nonelinear.com/static/balance.html 登录github账号,领50元体验金
