数据来源非线智能Nonelinear 非线智能团队,维护着GitHub上的开源项目 chinese-llm-benchmark,目前 6,000+ Stars,长期占据中文LLM商业评测类项目Star数第一
Anthropic发布了Claude Opus 4.8,并将其描述为一次"温和但可感知"的升级:相较Claude Opus 4.7,新版本重点提升了编码、智能体任务、知识工作和诚实性表现,同时在Claude Code中引入更动态的工作流支持。我们对其API版本claude-opus-4.8进行了全面评测,测试其在准确率、响应时间、token消耗和调用花费等关键指标上的表现。
需要说明的是,本次评测的是claude-opus-4.8非思考模式,并未测试Claude Opus 4.8的思考模式或Fast版本。本文所有"实测"数据均指非思考模式下的结果,评测维度覆盖教育、医疗、金融、法律、推理数学、语言指令、Agent工具调用以及coding等板块。
claude-opus-4.8非思考模式版本表现:
测试题数:约1.5万
总分(准确率):71.5%
平均耗时(每次调用):9s
平均token(每次调用消耗的token):819
平均花费(每千次调用的人民币花费):99.4
1、新旧对决
对比历史版本claude-opus-4.6,claude-opus-4.8非思考模式的变化并不是单纯的全面提升,而是呈现出非常明确的能力侧重:推理、Agent和coding维度上行,响应速度显著变快,但部分中文垂直领域出现回调。数据如下:


*数据来源:非线智能ReLE评测https://github.com/jeinlee1991/chinese-llm-benchmark
*输出价格单位: 元/百万token
整体性能小幅提升:新版本准确率从70.0%提升至71.5%,提升了1.5个百分点,榜单排名从第20位升至第11位。
推理与数学计算提升最明显:推理与数学计算从71.8%提升至76.6%,提升了4.8个百分点,是本次迭代中提升幅度最大的维度。这与官方强调更强复杂任务处理能力的方向基本一致。
Coding和Agent能力同步改善:coding从65.2%提升至69.5%(+4.3%),agent与工具调用从69.1%提升至73.1%(+4.0%)。这两项是Claude Opus 4.8官方最重视的方向,也是在本次ReLE细分数据中最能体现代际变化的部分。
医疗与语言维度小幅提升:医疗与心理健康从81.5%微增至82.1%(+0.6%),语言与指令遵从从63.0%提升至64.0%(+1.0%)。这两项变化幅度不大,更多体现为稳定补强。
部分中文垂直领域出现回调:教育从63.0%降至56.4%(-6.6%),金融从79.0%降至74.5%(-4.5%),法律与行政公务从82.7%降至79.0%(-3.7%)。这说明新版本的能力调整并没有均匀覆盖所有中文任务,尤其是知识密集和规则密集型题目仍存在一定波动。
响应速度显著提升:平均耗时从15s缩短至9s,降幅约40%。在总分提升的同时,响应时间明显下降,这是claude-opus-4.8非思考模式在本次实测中最突出的工程表现。
Token和成本基本稳定:平均token从794增至819,增加约3.1%;输出价格仍为175.0元/百万token。最终每千次调用花费从96.5元增至99.4元,增幅约3.0%。
2、横向对比
在当前主流大模型竞争格局中,claude-opus-4.8非思考模式作为Anthropic最新Opus系列模型表现如何?我们从三个维度进行横向对比分析:
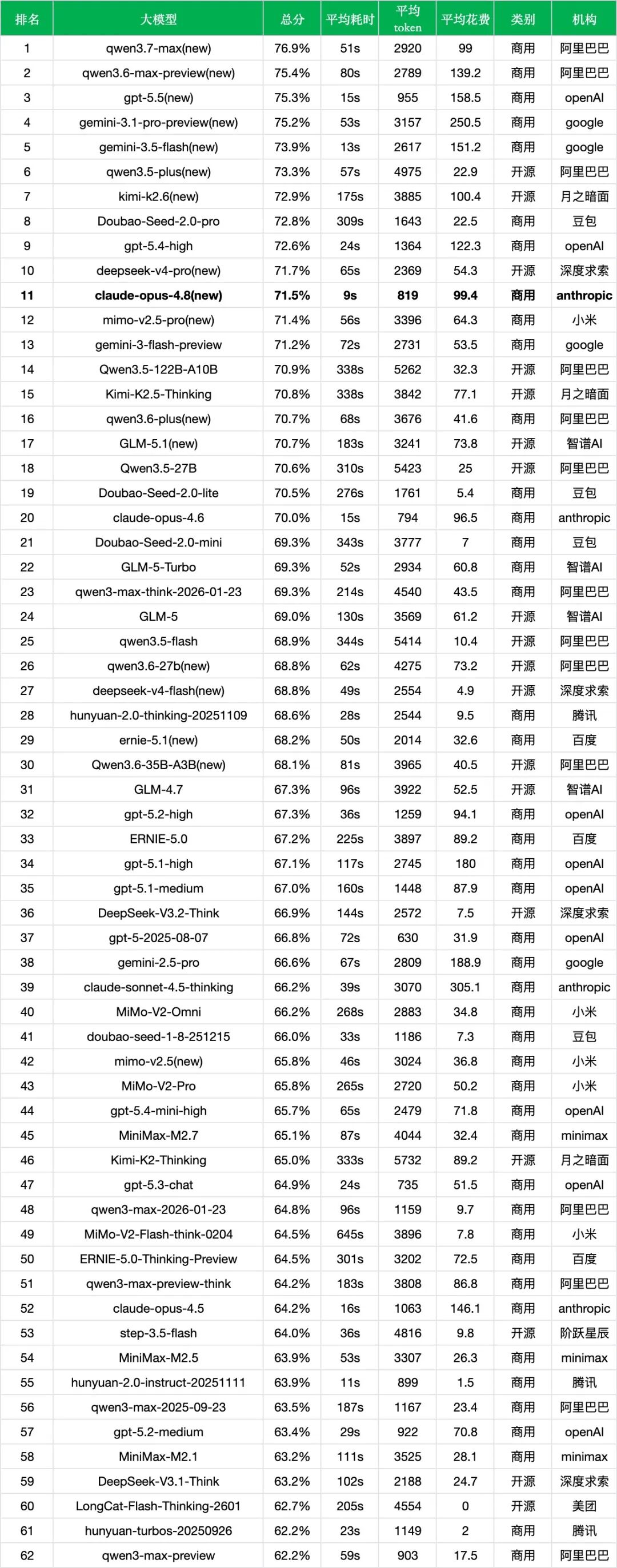
*数据来源:非线智能ReLE评测https://github.com/jeinlee1991/chinese-llm-benchmark
同成本档位对比
同成本档位:claude-opus-4.8(71.5%,99.4元)正好落在90至110元/千次区间。这个区间里有qwen3.7-max(76.9%,99元)、kimi-k2.6(72.9%,100.4元)、claude-opus-4.6(70.0%,96.5元)、gpt-5.2-high(67.3%,94.1元)和ERNIE-5.0(67.2%,89.2元)。仅看总分,Opus 4.8非思考模式不是这一档的最高分;它超过了上一代Opus和部分老旗舰,但与qwen3.7-max、kimi-k2.6仍有差距。
速度是最强差异化变量:claude-opus-4.8非思考模式平均耗时仅9s,是当前总榜前列模型中非常快的一档。相比同成本附近的qwen3.7-max(51s)、kimi-k2.6(175s)、claude-opus-4.6(15s),Opus 4.8非思考模式的低延迟优势非常明显。对于需要频繁调用、快速交互和多轮工具执行的Agent场景,这一指标更值得关注。
向上对比:相比gpt-5.5(75.3%,15s,158.5元)和gemini-3.5-flash(73.9%,13s,151.2元),claude-opus-4.8准确率分别低3.8和2.4个百分点,但花费低约三分之一,速度也更快。相比gemini-3.1-pro-preview(75.2%,53s,250.5元),Opus 4.8的准确率差距为3.7个百分点,但调用花费和响应时间都低得多。
向下看低成本替代方案:qwen3.5-plus(73.3%,22.9元)、Doubao-Seed-2.0-pro(72.8%,22.5元)、deepseek-v4-pro(71.7%,54.3元)等模型以更低成本取得了接近或更高的中文综合准确率。仅从中文文本准确率和调用成本看,claude-opus-4.8并不是成本效率比最突出的选择,如果任务更依赖快速多轮调用、代码协作和Agent工作流,它的速度优势才更容易体现价值。
新旧模型对比
Anthropic自身代际改善明确:claude-opus-4.8(71.5%)相比claude-opus-4.6(70.0%)提升1.5个百分点,排名从第20位升至第11位;相比claude-opus-4.5(64.2%)则提升7.3个百分点。
产品线更聚焦:当前榜单中,claude-opus-4.8(71.5%,第11位)是Anthropic表现最好的模型,其次是claude-opus-4.6(70.0%,第20位)、claude-sonnet-4.5-thinking(66.2%,第39位)和claude-opus-4.5(64.2%,第52位)。
与近期新模型对比:claude-opus-4.8(71.5%)低于qwen3.7-max(76.9%)、gpt-5.5(75.3%)、gemini-3.5-flash(73.9%)、kimi-k2.6(72.9%)、deepseek-v4-pro(71.7%),但高于mimo-v2.5-pro(71.4%)等模型。
开源VS闭源对比
闭源阵营中的低延迟高端模型:在闭源模型中,claude-opus-4.8非思考模式准确率高于mimo-v2.5-pro(71.4%)、gemini-3-flash-preview(71.2%)、Doubao-Seed-2.0-lite(70.5%)和claude-opus-4.6(70.0%),但低于qwen3.7-max、qwen3.6-max-preview、gpt-5.5、gemini-3.1-pro-preview、gemini-3.5-flash等头部模型。
开源阵营的成本效率比压力明显:qwen3.5-plus(73.3%,22.9元)、kimi-k2.6(72.9%,100.4元)、deepseek-v4-pro(71.7%,54.3元)、Qwen3.5-122B-A10B(70.9%,32.3元)等开源模型已经在榜单前列形成密集分布。其中qwen3.5-plus以不到四分之一的花费取得更高总分,deepseek-v4-pro也以约一半成本取得略高总分。对于纯中文文本任务和成本敏感场景,开源阵营仍然有很强吸引力。
选型逻辑看任务形态:Anthropic官方对Opus 4.8的定位更偏复杂代码协作、长程Agent任务、知识工作和诚实性。从本次ReLE结果看,Opus 4.8非思考模式在agent与工具调用、coding、推理数学三个方向都有明确提升,同时平均耗时降至9s。对于需要多轮快速迭代的Agent系统,这种能力结构可能比单轮总分更接近真实使用价值。
3、官方评测
根据Anthropic官方博客(https://www.anthropic.com/news/claude-opus-4-8),Claude Opus 4.8是一款面向编码、智能体任务和知识工作的升级版模型。官方称其相较Opus 4.7并非大版本重构,而是一次"modest but tangible improvement",重点体现在基准测试、真实使用反馈、诚实性和Claude Code工作流上。
编码、Agent与知识工作基准
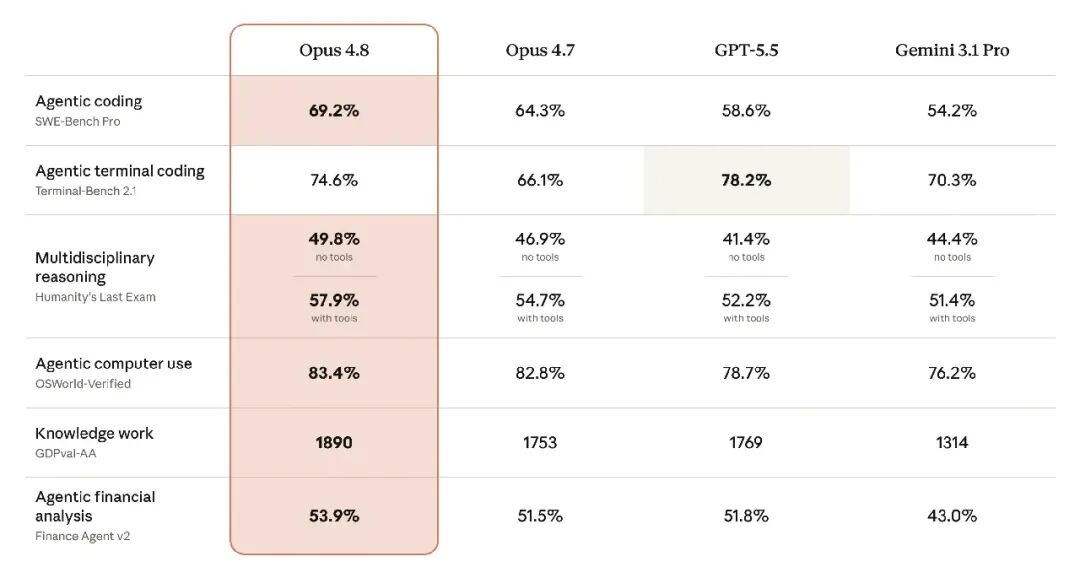
官方披露,Claude Opus 4.8在多项主流基准上相较Claude Opus 4.7有稳定提升,并与GPT-5.5、Gemini 3.1 Pro进行了对比:
SWE-Bench Pro:69.2%,高于Claude Opus 4.7的64.3%,也高于GPT-5.5的58.6%和Gemini 3.1 Pro的54.2%。这是官方最能体现代码仓库级问题修复能力的指标之一。
Terminal-Bench 2.1:74.6%,高于Claude Opus 4.7的66.1%和Gemini 3.1 Pro的70.3%,但低于GPT-5.5的78.2%。官方同时注明,在Codex CLI环境下,GPT-5.5可达到83.4%。
Humanity's Last Exam:无工具条件下,Claude Opus 4.8为49.8%,高于Opus 4.7的46.9%、GPT-5.5的41.4%和Gemini 3.1 Pro的44.4%;带工具条件下,Opus 4.8为57.9%,同样高于上述对比模型。
OSWorld-Verified:Claude Opus 4.8达到83.4%,略高于Opus 4.7的82.8%,并高于GPT-5.5的78.7%和Gemini 3.1 Pro的76.2%。这一基准主要衡量模型在真实计算机环境中的任务执行能力。
GDPval-AA:Claude Opus 4.8得分1890,高于Opus 4.7的1753、GPT-5.5的1769和Gemini 3.1 Pro的1314,体现其在知识工作任务中的竞争力。
Finance Agent v2:Claude Opus 4.8为53.9%,高于Opus 4.7的51.5%、GPT-5.5的51.8%和Gemini 3.1 Pro的43.0%。
诚实性与安全表现
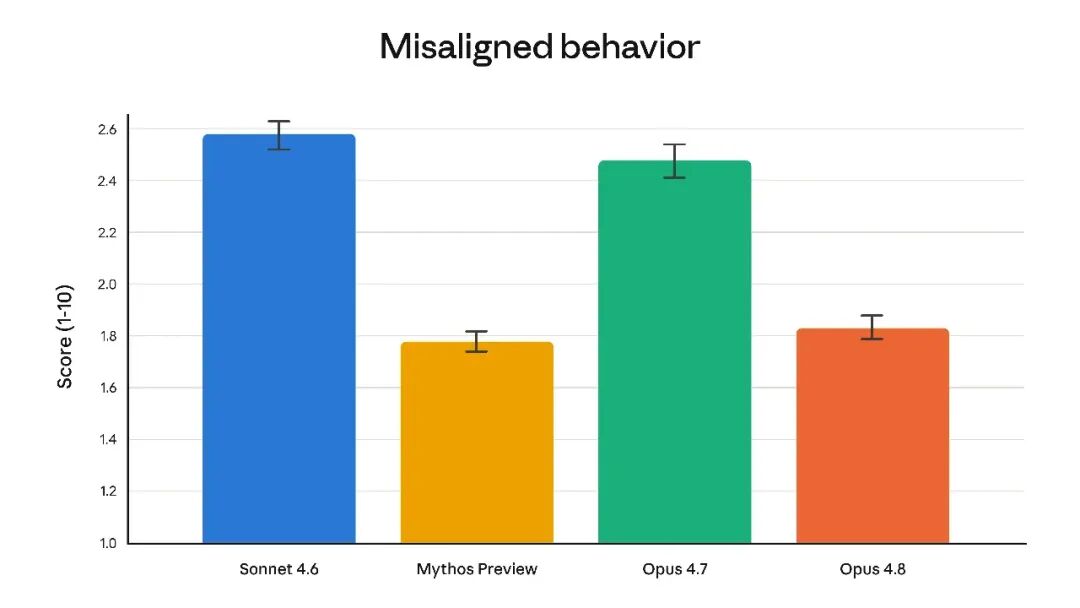
Anthropic在博客中强调,Claude Opus 4.8在诚实性上有明显改善。官方称,在一次长程代码库迁移测试中,Opus 4.8对于引入的缺陷保持沉默的概率比Opus 4.7低4倍左右。这类指标与传统准确率不同,更关注模型是否会在协作过程中隐瞒问题、过度承诺或忽略已知风险。
官方同时提到,Opus 4.8在高风险滥用相关评估中表现更稳,尤其在网络安全和生化安全相关防护上有所改进。对于企业Agent和代码协作场景,模型是否能如实报告限制、风险和失败状态,会直接影响真实部署中的可控性。
非线智能官网https://nonelinear.com 已上线Claude Opus 4.8版,欢迎深度体验。 同时,非线智能API可连接超480+全球模型,支持一键Api聚合以及Api中转,提供稳定的企业级服务。 登录github账号,领20-50元体验金。接入Claude Opus 4.8就用非线智能API。

