Google在I/O 2026期间发布了Gemini 3.5系列,并率先推出Gemini 3.5 Flash。与很多人对"Flash"系列的低成本、快响应印象不同,Google这次对Gemini 3.5 Flash的定位更偏向前沿Agent与Coding能力:在保持Flash系列速度优势的同时,面向长程智能体任务、复杂代码工作流和多模态理解提供更强的能力底座。我们对其API版本gemini-3.5-flash进行了全面评测,测试其在准确率、响应时间、token消耗和调用花费等关键指标上的表现。
需要说明的是,本次评测侧重中文场景下的综合能力考察,评测维度覆盖教育、医疗、金融、法律、推理数学、语言指令、Agent工具调用以及coding等板块。Gemini 3.5 Flash官方主推的长程Agent、多智能体协作、多模态图表理解等能力,并不能完全被中文文本准确率指标覆盖。对于这部分能力,读者可结合文末的官方评测数据形成更完整的判断。
gemini-3.5-flash版本表现:
测试题数:约1.5万
总分(准确率):73.9%
平均耗时(每次调用):13s
平均token(每次调用消耗的token):2617
平均花费(每千次调用的人民币花费):151.2
1、新旧对决
对比上一代版本gemini-3-flash-preview,gemini-3.5-flash的变化并不是简单的"更便宜、更快",而是在速度大幅提升的同时,将能力重心明显推向coding和Agent工具调用。数据如下:


*数据来源:非线智能ReLE评测https://github.com/jeinlee1991/chinese-llm-benchmark
*输出价格单位: 元/百万token
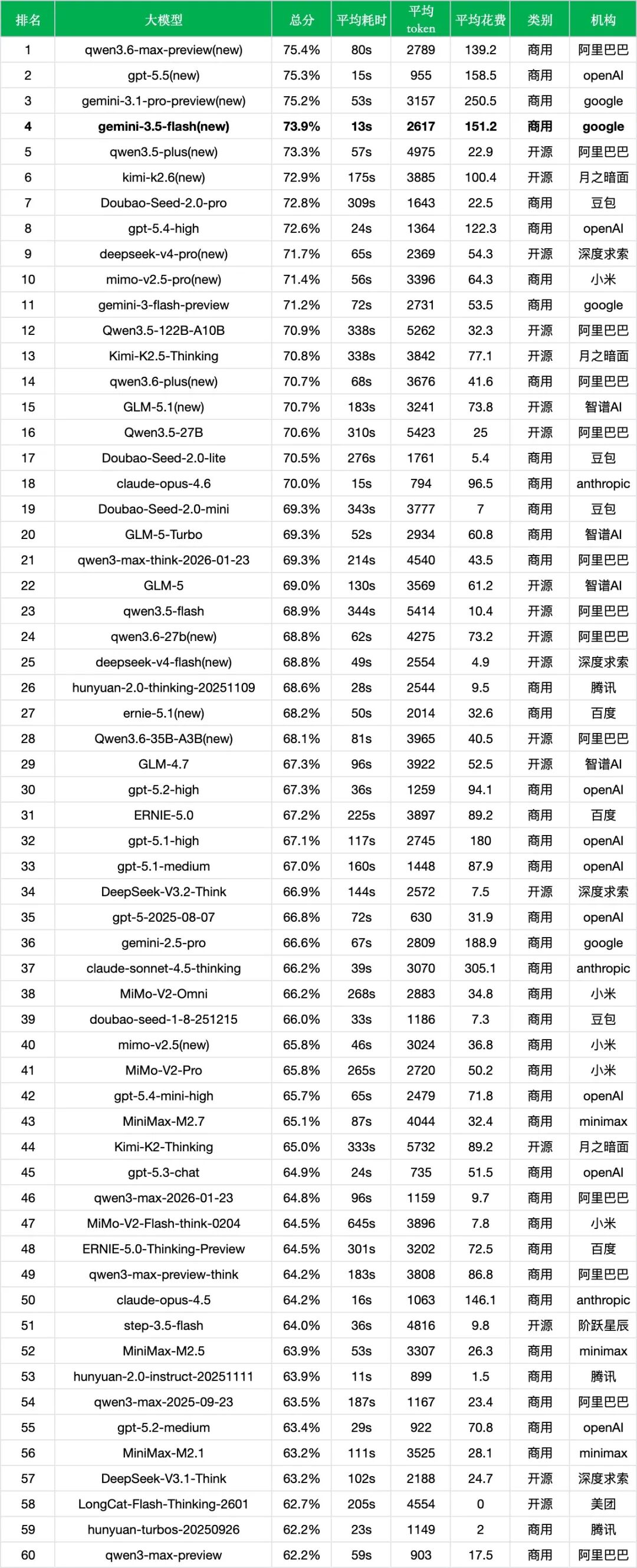
整体性能稳步提升:新版本准确率从71.2%提升至73.9%,提升了2.7个百分点,榜单排名从第11位上升至第4位,进入当前主流模型头部梯队。
Agent与工具调用提升最明显:agent与工具调用从48.6%提升至57.5%,提升了8.9个百分点,是本次迭代中提升幅度最大的维度。这与Google官方强调的"面向复杂Agent工作流"定位基本一致。
Coding能力明显增强:coding从66.0%提升至74.2%,提升了8.2个百分点。结合官方在Terminal-Bench 2.1、MCP Atlas等编程与Agent基准上的成绩来看,gemini-3.5-flash并不是传统意义上的轻量聊天模型,而是将代码与工具执行作为核心升级方向。
推理和教育维度小幅提升:推理与数学计算从83.4%提升至84.5%(+1.1%),教育从63.5%提升至64.9%(+1.4%),医疗与心理健康从87.2%微增至87.5%(+0.3%)。这些变化幅度不算大,但整体保持了上一代的基础能力。
部分维度出现回调:金融从84.0%降至80.9%(-3.1%),法律与行政公务从83.3%降至81.3%(-2.0%),语言与指令遵从从72.2%降至71.1%(-1.1%)。这说明新版本在能力调优中并非所有中文垂直任务都同步受益,尤其是金融、法律等密集型任务仍存在一定波动。
响应速度大幅提升:平均耗时从72s缩短至13s,降幅约82%。在总分提升的同时,响应速度接近提升到上一代的5.5倍,也是gemini-3.5-flash最突出的工程表现。
Token消耗略有下降,但成本明显上升:平均token从2731降至2617,下降约4.2%;但输出价格从21.3元/百万token上调至63.0元/百万token,约为上一代的3倍。最终每千次调用花费从53.5元升至151.2元,增加约97.7元。也就是说,新版本的核心交换并不是"更省钱",而是用接近3倍的调用成本,换取更强的Agent/Coding能力和显著更低的响应延迟。
2、横向对比
在当前主流大模型竞争格局中,gemini-3.5-flash作为Google面向Agent与Coding场景的新一代Flash模型表现如何?我们从三个维度进行横向对比分析:
*数据来源:非线智能ReLE评测https://github.com/jeinlee1991/chinese-llm-benchmark
同成本档位对比
140至160元/千次区间的头部竞争:gemini-3.5-flash(73.9%,151.2元)所在区间的主要参照对象包括qwen3.6-max-preview(75.4%,139.2元)、gpt-5.5(75.3%,158.5元)和claude-opus-4.5(64.2%,146.1元)等。在这个成本区间内,gemini-3.5-flash总分低于qwen3.6-max-preview和gpt-5.5约1.4至1.5个百分点,但明显高于claude-opus-4.5。
速度是最突出的差异化变量:gemini-3.5-flash平均耗时为13s,是总榜前十中最快的模型。相比qwen3.6-max-preview(80s)、gemini-3.1-pro-preview(53s)、kimi-k2.6(175s)、Doubao-Seed-2.0-pro(309s)等模型,gemini-3.5-flash在延迟上具备明显优势。即便与gpt-5.5(15s)相比,也略快一些。
向上对比Google自家Pro线:gemini-3.1-pro-preview(75.2%,250.5元)准确率高出1.3个百分点,但平均耗时为53s,平均花费也高出约66%。gemini-3.5-flash以更低成本和更快响应提供了接近Pro级别的中文综合准确率。
向下看低成本替代方案:qwen3.5-plus(73.3%,22.9元)、Doubao-Seed-2.0-pro(72.8%,22.5元)、deepseek-v4-pro(71.7%,54.3元)等模型以显著更低的成本提供了接近的中文综合准确率。仅从中文文本评测的成本效率比看,gemini-3.5-flash并不占优,其价值更多体现在低延迟、Google生态、多模态和Agent工具链上。
新旧模型对比
自身代际变化清晰:gemini-3.5-flash(73.9%)相比gemini-3-flash-preview(71.2%)提升2.7个百分点,排名从第11位升至第4位。更重要的是,平均耗时从72s缩短至13s,说明这次迭代同时解决了上一代Flash Preview在速度和头部能力上的部分短板。
Google产品线定位更分明:从榜单看,gemini-3.1-pro-preview(75.2%,第3位)仍是Google在中文综合评测中的Pro级代表;gemini-3.5-flash(73.9%,第4位)紧随其后,以更低延迟和更低花费承接大规模Agent与开发者场景;gemini-3-flash-preview(71.2%,第11位)和gemini-2.5-pro(66.6%,第36位)则形成上一代参照。Google的产品线正在从"Pro负责能力、Flash负责速度"转向"Flash也承担前沿Agent能力"。
开源VS闭源对比
闭源阵营中的高速头部模型:在闭源模型中,gemini-3.5-flash的准确率高于Doubao-Seed-2.0-pro(72.8%)、gpt-5.4-high(72.6%)、gemini-3-flash-preview(71.2%)、claude-opus-4.6(70.0%)等模型,同时保持13s的平均耗时。与同样低延迟的gpt-5.5(75.3%,15s)相比,gemini-3.5-flash准确率低1.4个百分点,但速度略快,成本也略低。
开源阵营的成本效率比压力仍然明显:qwen3.5-plus(73.3%,22.9元)、kimi-k2.6(72.9%,100.4元)、deepseek-v4-pro(71.7%,54.3元)、Qwen3.5-122B-A10B(70.9%,32.3元)等开源模型已经在总榜前列形成密集分布。对于纯中文文本任务和成本敏感场景,开源阵营依然有很强吸引力。
3、官方评测
根据Google官方博客(https://blog.google/innovation-and-ai/models-and-research/gemini-models/gemini-3-5/),Gemini 3.5系列的核心定位是"frontier intelligence with action",即将前沿智能与可执行能力结合起来。Google率先发布的是Gemini 3.5 Flash,并明确表示Gemini 3.5 Pro已经在内部使用,预计下个月推出。
Agent与Coding能力
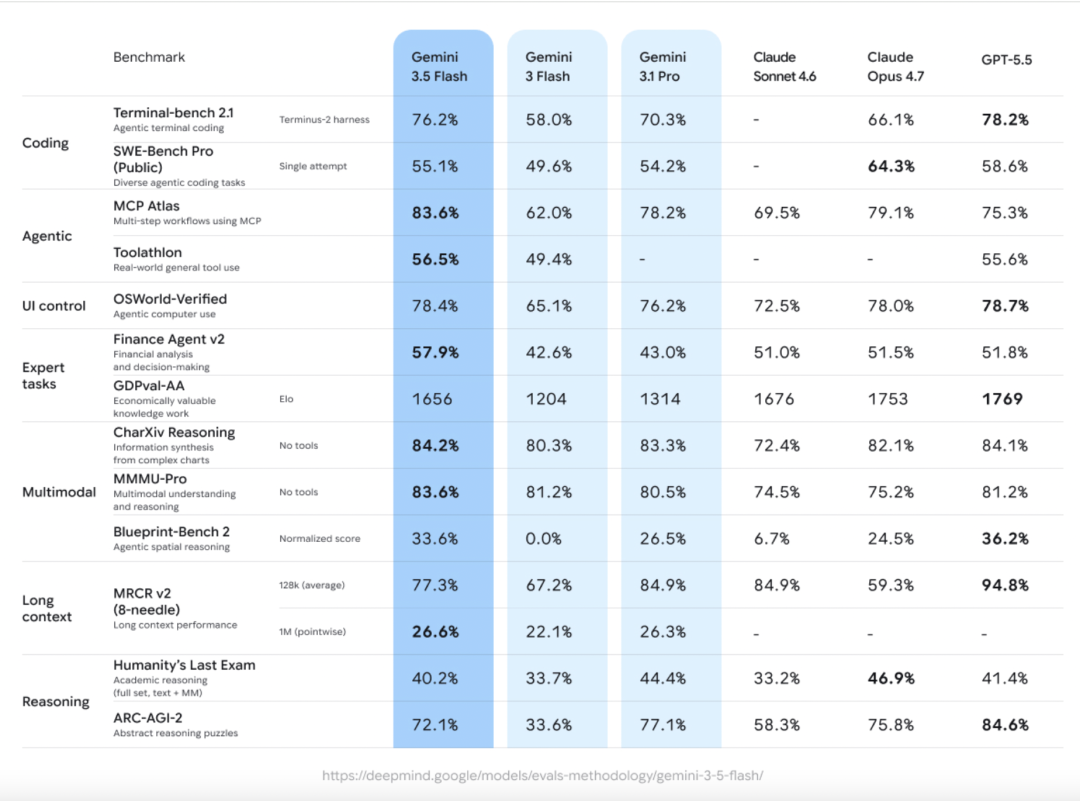
Google称Gemini 3.5 Flash是其目前最强的Agent与Coding模型,在多个编程和智能体基准上超过Gemini 3.1 Pro。官方披露的关键数据包括:
Terminal-Bench 2.1:76.2%,用于衡量复杂命令行与多步骤工程任务能力。
GDPval-AA:1656 Elo,用于评测知识工作和企业任务表现。
MCP Atlas:83.6%,用于评测模型在MCP工具生态中的执行能力。
CharXiv Reasoning:84.2%,用于衡量多模态图表与视觉推理能力。
官方还强调,在输出token速度上,Gemini 3.5 Flash比其他前沿模型快4倍。
速度与智能的平衡
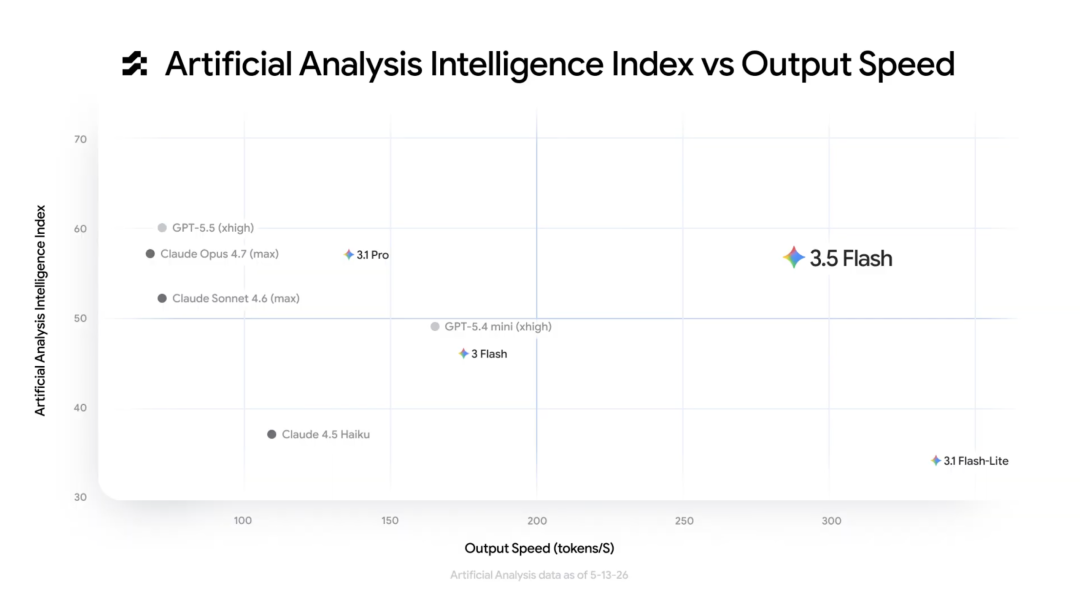
Google在博客中引用Artificial Analysis指数,将Gemini 3.5 Flash放在"高智能、高输出速度"的象限中,强调它不再要求用户在质量和延迟之间做强取舍。
长程Agent任务与多智能体协作
官方展示了多类由Gemini 3.5 Flash驱动的Agent任务案例,包括在Google Antigravity中自动重命名和分类非结构化资产、使用两个智能体综合AlphaZero论文并在6小时内编码完成可玩的游戏、将混乱的遗留代码库迁移到Next.js、并行生成城市景观,以及通过builder和player两个智能体循环改进游戏。
多模态与交互式生成
Google还强调,Gemini 3.5 Flash继承Gemini 3系列的多模态基础,能够生成更丰富的交互式Web UI和图形。官方案例包括根据论文生成交互式动画、将文本描述转化为交互式硬件示意、并行生成完整品牌概念,以及在60秒内生成不同的结账流程UX方案。
非线智能官网https://nonelinear.com 已上线Gemini 3.5 Flash版,欢迎深度体验。 同时,非线智能API可连接超480个全球模型,支持一键Api聚合以及Api中转,提供稳定的企业级服务。 登录github账号,领50元体验金。接入Deepseek就用非线智能API。

