月之暗面在Kimi K2.6之后推出了面向编程场景的新模型Kimi K2.7 Code,官方将其定位为目前Kimi体系中最强的Coding模型,重点强化长上下文编码、长程任务执行、指令遵从以及Agent能力。本次我们对其API版本kimi-k2.7-code进行了全面评测,测试其在准确率、响应时间、token消耗和调用花费等关键指标上的表现。
需要说明的是,kimi-k2.7-code并不是一个普通聊天模型的常规续代。官方文档明确写到,kimi-k2.7-code不支持非思考模式,thinking参数默认开启,关闭会报错。同时,本次评测侧重中文文本场景下的综合能力考察。
kimi-k2.7-code版本表现:
测试题数:约1.5万
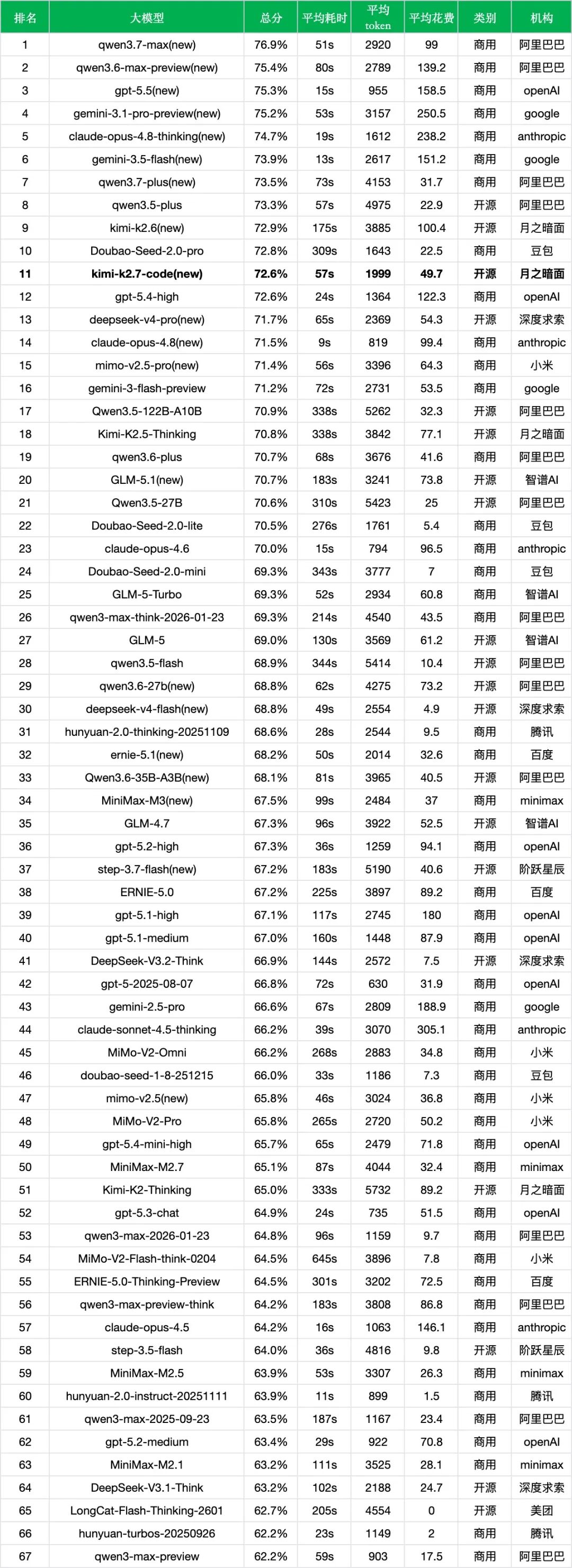
总分(准确率):72.6%
平均耗时(每次调用):57s
平均token(每次调用消耗的token):1999
平均花费(每千次调用的人民币花费):49.7
1、新旧对决
对比上一代版本kimi-k2.6,kimi-k2.7-code的变化不是单纯追求更高总分,而是一次更偏工程效率和Agent能力的调整:综合准确率基本持平,Agent与多个中文垂直领域有所改善,但推理数学和coding分项出现回调;与此同时,响应时间、token消耗和调用成本都明显下降。数据如下:


*数据来源:非线智能ReLE评测https://github.com/jeinlee1991/chinese-llm-benchmark
*输出价格单位: 元/百万token
整体性能基本持平:kimi-k2.7-code总分为72.6%,相比kimi-k2.6的72.9%下降0.3个百分点,榜单排名从第9位调整至第11位。这个变化幅度很小,更接近同一能力区间内的结构调整。
Agent与工具调用改善明确:agent与工具调用从63.2%提升至66.9%,提升3.7个百分点,是本次细分项中增幅最大的一项。这与官方强调kimi-k2.7-code强化Agentic能力的方向相吻合。
法律与行政公务也有较明显提升:该维度从80.3%提升至83.3%,提升3.0个百分点;医疗与心理健康从89.3%提升至90.8%(+1.5%),语言与指令遵从从71.6%提升至73.0%(+1.4%),金融从86.4%提升至87.0%(+0.6%),教育从62.4%提升至62.9%(+0.5%)。这些变化说明kimi-k2.7-code并没有只在代码方向做窄化优化,部分中文垂直任务也得到了补强。
推理数学和coding出现回调:推理与数学计算从82.5%降至78.7%(-3.8%),coding从62.6%降至57.6%(-5.0%)。尤其是coding分项回调。
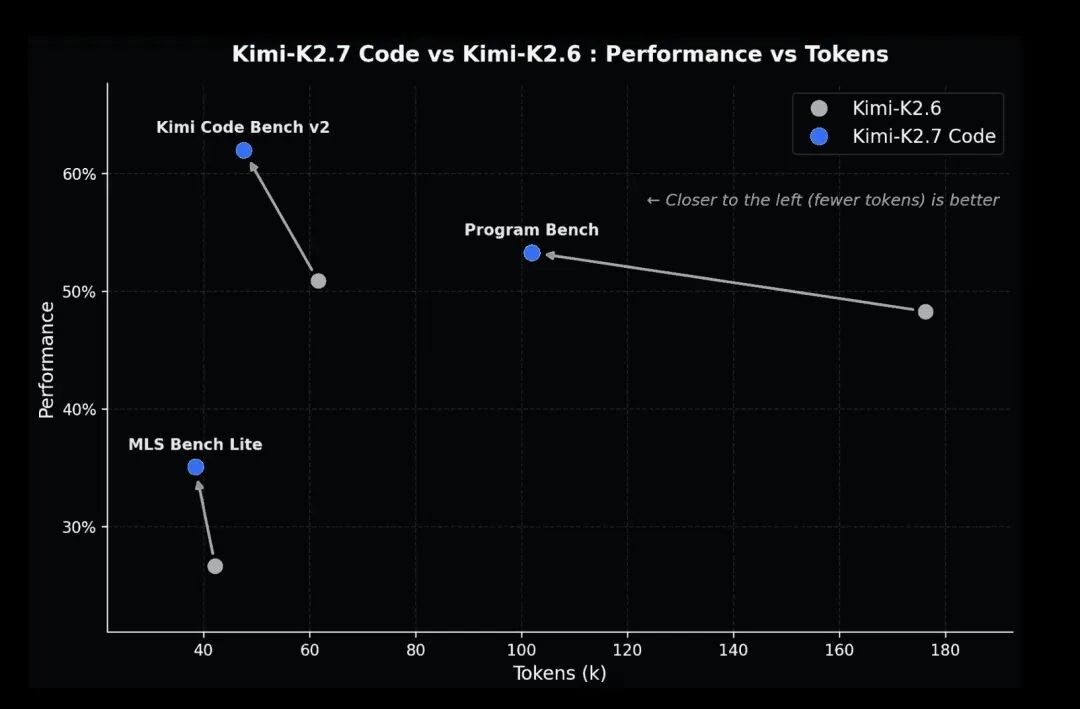
响应速度明显改善:平均耗时从175s缩短至57s,减少118s,耗时下降约67%。对于需要频繁调用的代码助手和Agent流程,这个变化比0.3个百分点的总分波动更有实际意义。
Token消耗接近减半:平均token从3885降至1999,减少约48.5%。在官方强调减少过度思考的背景下,这个结果比较关键:模型不再通过非常长的输出或推理链来维持表现,而是在更短输出中保持了接近kimi-k2.6的中文综合准确率。
成本下降更直接:两代模型输出价格均为27.0元/百万token,但由于kimi-k2.7-code平均token明显减少,每千次调用花费从100.4元降至49.7元,下降约50.5%。
2、横向对比
在当前主流大模型竞争格局中,kimi-k2.7-code作为月之暗面面向代码和Agent场景的新模型表现如何?我们从三个维度进行横向对比分析:
*数据来源:非线智能ReLE评测https://github.com/jeinlee1991/chinese-llm-benchmark
同成本档位对比
50元附近看站位:kimi-k2.7-code(72.6%,49.7元)处在40至60元/千次调用区间,主要参照对象包括deepseek-v4-pro(71.7%,54.3元)、gemini-3-flash-preview(71.2%,53.5元)、qwen3.6-plus(70.7%,41.6元)、GLM-4.7(67.3%,52.5元)和gpt-5.3-chat(64.9%,51.5元)。在这一档里,kimi-k2.7-code的中文综合总分处于前列,并且花费低于deepseek-v4-pro和gemini-3-flash-preview。
速度不是最强项,但比kimi-k2.6实用很多:kimi-k2.7-code平均耗时57s,与deepseek-v4-pro(65s)、gemini-3-flash-preview(72s)、qwen3.6-plus(68s)处在接近区间。不过相比kimi-k2.6的175s,kimi-k2.7-code已经把月之暗面开源旗舰模型的调用体验拉回到更可用的速度区间。
往低档位看:qwen3.7-plus(73.5%,31.7元)、qwen3.5-plus(73.3%,22.9元)、Doubao-Seed-2.0-pro(72.8%,22.5元)都以更低成本取得了略高总分。仅从中文综合准确率和调用成本看,kimi-k2.7-code并不是最极致的成本效率比选择;它更适合放在代码、长上下文、Agent和开放生态的框架下评估。
往高档位看:与gpt-5.4-high(72.6%,122.3元)相比,kimi-k2.7-code总分相同,花费不到一半,但耗时更长;与kimi-k2.6(72.9%,100.4元)相比,kimi-k2.7-code总分低0.3个百分点,但成本约减半、耗时约降至三分之一。
新旧模型对比
月之暗面这次更像是在做效率修正:从kimi-k2.6到kimi-k2.7-code,总分没有继续上探,反而从72.9%微降至72.6%;但平均耗时从175s降至57s,平均token从3885降至1999,每千次调用花费从100.4元降至49.7元。相比单纯涨分,这次迭代更像是在解决kimi-k2.6的调用成本和响应时间问题。
Kimi产品线位置更清晰:当前榜单中,月之暗面模型从高到低依次是kimi-k2.6(72.9%,第9位)、kimi-k2.7-code(72.6%,第11位)、Kimi-K2.5-Thinking(70.8%,第18位)和Kimi-K2-Thinking(65.0%,第51位)。kimi-k2.7-code不是总分最高的Kimi模型,但它把成本和延迟压到了更可接受的区间,同时保留了接近kimi-k2.6的综合表现。
放到近期新模型里看:kimi-k2.7-code(72.6%)低于qwen3.7-max(76.9%)、gpt-5.5(75.3%)、gemini-3.5-flash(73.9%)、qwen3.7-plus(73.5%)等,但高于deepseek-v4-pro(71.7%)、claude-opus-4.8(71.5%)、mimo-v2.5-pro(71.4%)。它处在当前榜单头部第二梯队的上沿。
开源VS闭源对比
开放权重阵营里的新高位:按榜单类别,kimi-k2.7-code属于开源模型。与开源阵营对比,它低于qwen3.5-plus(73.3%,22.9元)和kimi-k2.6(72.9%,100.4元),但高于deepseek-v4-pro(71.7%,54.3元)、Qwen3.5-122B-A10B(70.9%,32.3元)、Kimi-K2.5-Thinking(70.8%,77.1元)和GLM-5.1(70.7%,73.8元)。
闭源阵营的压力主要来自头部商用模型:qwen3.7-max(76.9%,99元)、qwen3.6-max-preview(75.4%,139.2元)、gpt-5.5(75.3%,158.5元)、gemini-3.1-pro-preview(75.2%,250.5元)等闭源或商用头部模型总分更高。kimi-k2.7-code的优势不在绝对总分,而在开放权重、较低成本和代码Agent定位的组合。
选型逻辑要看任务形态:如果需要开放模型、较长上下文、代码协作和可控的多轮Agent调用,kimi-k2.7-code的价值更容易体现。尤其是相比kimi-k2.6,它把成本和速度问题压下去之后,更适合进入实际工程链路。
3、官方评测
根据月之暗面官方文档(https://platform.kimi.ai/docs/guide/kimi-k2-7-code-quickstart),Kimi K2.7 Code是Kimi当前最强的Coding模型。官方强调,它在长上下文中有更好的指令遵从能力,能以更高成功率完成编码任务,并在外部基准评测中相较K2.6改善了长程编码表现,同时平均减少30%的过度思考倾向。
长程编码与指令遵从
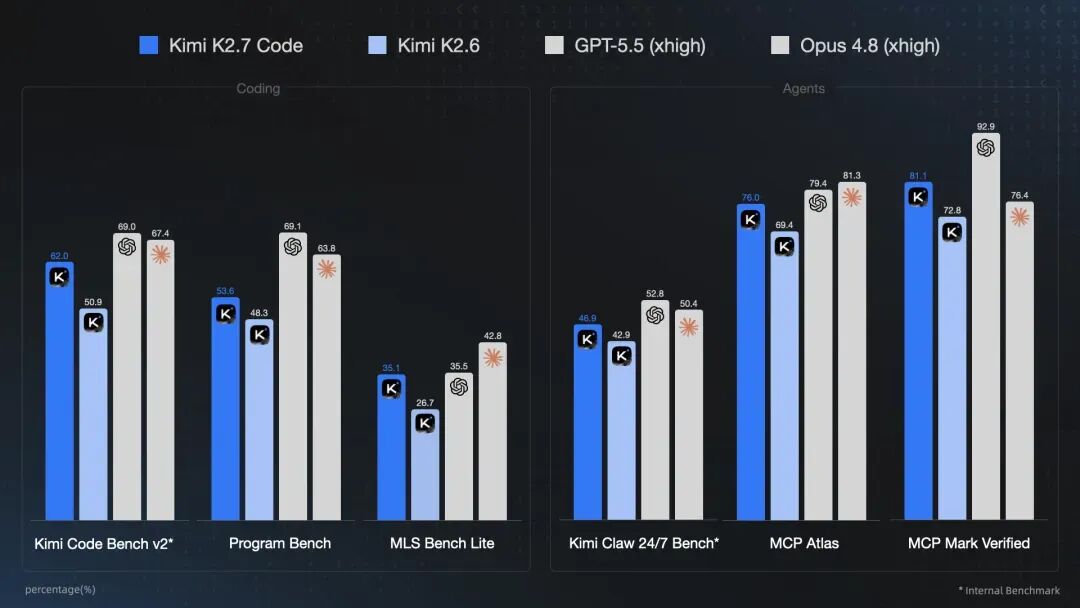
官方将K2.7 Code的核心改进放在长程编码和指令遵从上,而不是一般聊天场景。文档称,外部基准评测显示,K2.7 Code相较K2.6在指令遵从和long-horizon coding performance上都有明显改善,并且平均减少30%的overthinking tendency。
Agent能力增强
官方文档提到,K2.7 Code在外部评测中的Agentic能力相较K2.6提升10%。
官方还给出了多模态工具调用示例:K2.7 Code可以结合视觉理解和工具调用处理视频片段分析任务。文档中展示的示例使用OpenAI兼容接口,并通过自定义工具读取视频片段,再把工具结果回填给模型继续推理。这说明官方希望把K2.7 Code放在"代码模型+多模态工具+Agent循环"的组合中使用。
非线智能官网https://nonelinear.com 已上线kimi-k2.7-code版,欢迎深度体验。 同时,非线智能API可连接超480+全球模型,支持一键Api聚合以及Api中转,提供稳定的企业级服务。 登录github账号,领20-50元体验金。接入kimi-k2.7-code就用非线智能API。

