阶跃星辰在Step 3.5 Flash之后,发布了新一代Step 3.7 Flash。官方将其定位为面向真实Agent场景的高效率Flash模型,强调多模态理解与行动、Web与视觉搜索增强、稳定工具调用与编排,以及对主流Agent生态的兼容。本次我们对其API版本step-3.7-flash进行了全面评测,测试其在准确率、响应时间、token消耗和调用花费等关键指标上的表现。
需要说明的是,本次评测侧重中文场景下的综合能力考察,评测维度覆盖教育、医疗、金融、法律、推理数学、语言指令、Agent工具调用以及coding等板块。而Step 3.7 Flash官方主推的Web搜索、多模态Agent、跨Agent框架兼容等能力,可以结合官方评测内容获取更全面的了解。
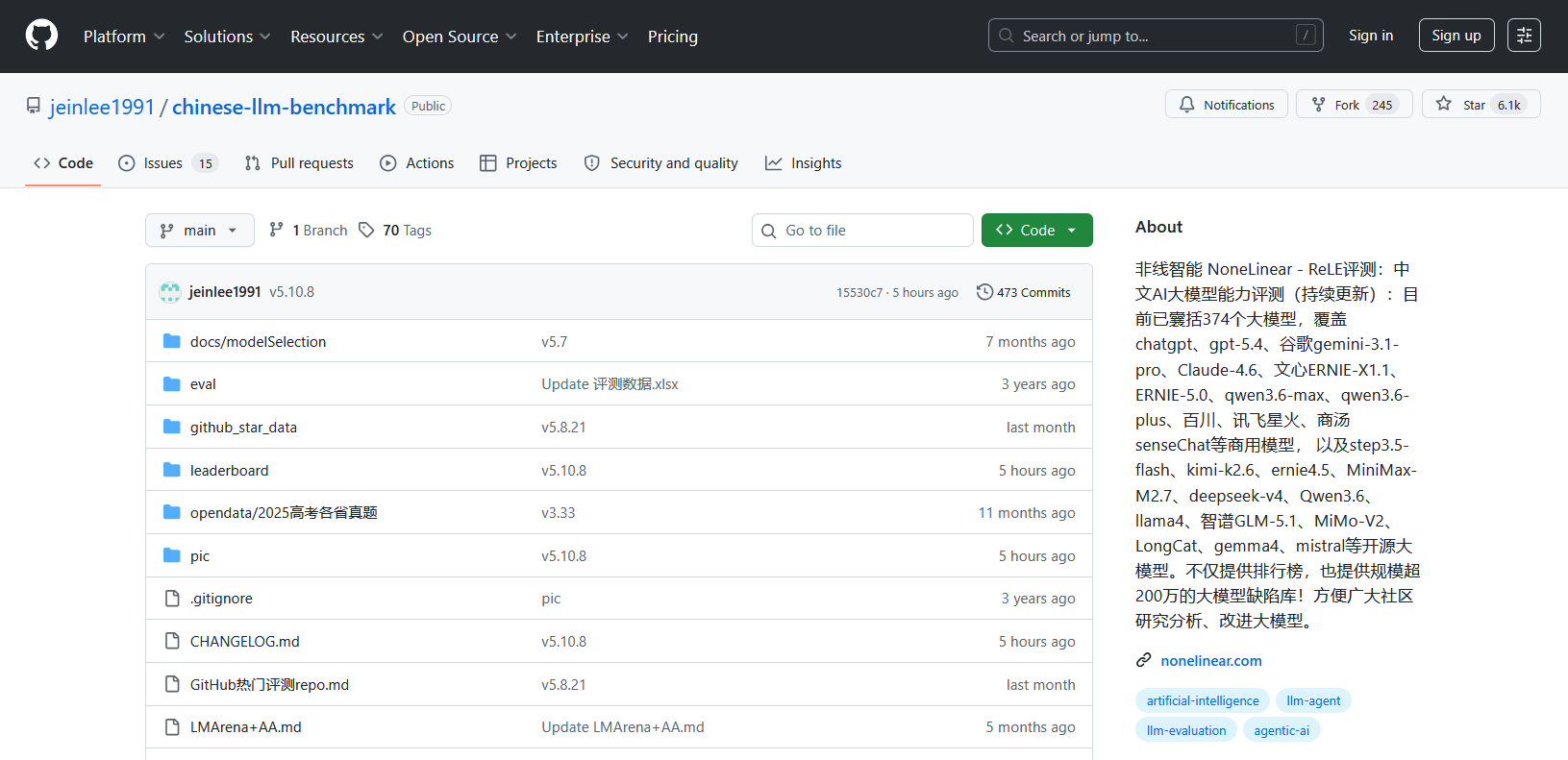
step-3.7-flash版本表现:
测试题数:约1.5万
总分(准确率):67.2%
平均耗时(每次调用):183s
平均token(每次调用消耗的token):5190
平均花费(每千次调用的人民币花费):40.6
1、新旧对决
对比上一代版本(step-3.5-flash),step-3.7-flash在总分和Agent相关能力上有所提升,但平均耗时、输出价格和调用花费也明显增加,数据如下:


*数据来源:非线智能ReLE评测https://github.com/jeinlee1991/chinese-llm-benchmark
*输出价格单位: 元/百万token
整体性能有所提升:新版本总分从64.0%提升至67.2%,提升了3.2个百分点,榜单排名从第56位上升至第35位。对于Flash定位模型而言,这属于一次明确的能力补强。
Agent与工具调用提升最明显:agent与工具调用维度从57.1%提升至69.9%(+12.8%),是本次迭代中变化最大的维度。这与官方强调的工具调用、编排稳定性和Agent生态兼容方向一致。
教育与金融维度稳步改善:教育从49.4%提升至54.7%(+5.3%),金融从71.3%提升至76.1%(+4.8%),说明新版本在知识理解和场景化问答上的表现有所增强。
语言与推理维度小幅提升:语言与指令遵从从53.6%提升至57.2%(+3.6%),推理与数学计算从75.2%提升至78.0%(+2.8%)。这两项提升幅度不算大,但与总分变化方向一致。
医疗维度基本持平:医疗与心理健康从79.1%提升至80.8%(+1.7%),变化幅度相对有限,整体保持在上一代基础上略有改善。
法律与coding出现回调:法律与行政公务从78.3%降至69.0%(-9.3%),coding从60.9%降至58.9%(-2.0%)。尤其法律维度回调较明显,说明新版本在Agent能力增强之外,并非所有传统文本任务都同步提升。
响应时间明显变长:平均耗时从36s增至183s,约为上一代的5.1倍。结合Agent维度的大幅提升,这可能反映出新版本在部分任务中采用了更长的推理或工具规划过程,但在对延迟敏感的应用中需要重点关注。
Token消耗与调用花费同步增加:平均token从4816增至5190(+7.8%),输出价格从2.1元/百万token上调至8.1元/百万token,每千次调用花费从9.8元增至40.6元,约为上一代的4.1倍。
2、横向对比
在当前主流大模型竞争格局中,step-3.7-flash作为阶跃星辰面向真实Agent场景的新一代Flash模型表现如何?我们从三个维度进行横向对比分析:
*数据来源:非线智能ReLE评测https://github.com/jeinlee1991/chinese-llm-benchmark
同成本档位对比
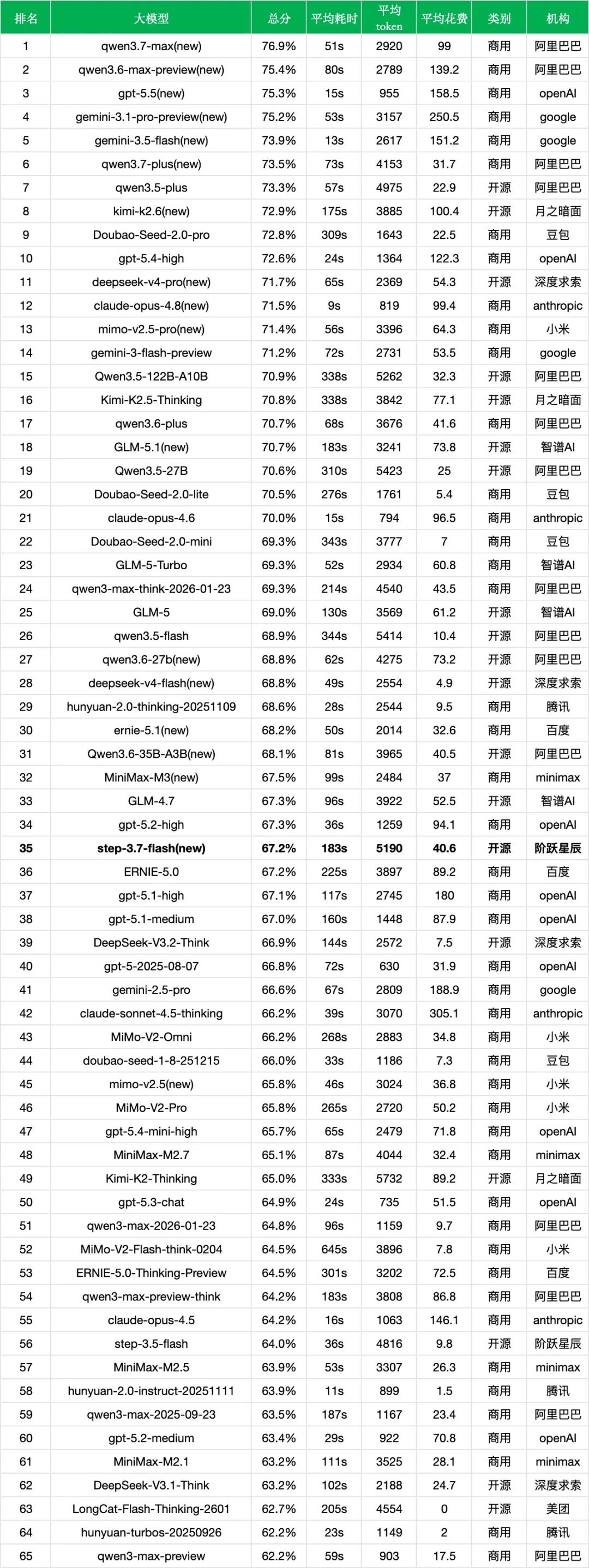
30至50元/千次区间内并不占优:step-3.7-flash(67.2%,40.6元)所在成本区间中,可比模型包括qwen3.7-plus(73.5%,31.7元)、Qwen3.5-122B-A10B(70.9%,32.3元)、qwen3.6-plus(70.7%,41.6元)、qwen3-max-think-2026-01-23(69.3%,43.5元)、Qwen3.6-35B-A3B(68.1%,40.5元)和MiniMax-M3(67.5%,37.0元)。仅从中文综合准确率和调用花费看,step-3.7-flash在同档位中并不处于前列。
与低成本Flash模型相比,成本效率比压力更明显:deepseek-v4-flash(68.8%,4.9元)、qwen3.5-flash(68.9%,10.4元)、Doubao-Seed-2.0-lite(70.5%,5.4元)、hunyuan-2.0-thinking-20251109(68.6%,9.5元)都以更低调用花费取得了更高总分。对当前中文综合场景而言,step-3.7-flash的成本效率比并不突出。
平均耗时长:step-3.7-flash平均耗时为183s,明显慢于同成本区间的qwen3.7-plus(73s)、qwen3.6-plus(68s)、Qwen3.6-35B-A3B(81s)和MiniMax-M3(99s)。如果任务对实时响应要求较高,这一指标需要单独评估。
新旧模型对比
代际能力提升明确:相比step-3.5-flash(64.0%,9.8元),step-3.7-flash总分提升3.2个百分点,排名上升21位,尤其Agent与工具调用维度提升12.8个百分点。可以看出,阶跃星辰这次迭代的重心并不只是压低成本,而是将Flash模型往更复杂的Agent任务上推进。
代际成本变化同样明显:step-3.7-flash的平均花费从9.8元增至40.6元,平均耗时从36s增至183s。若只看中文综合评测,新增能力的成本代价较高;若放到官方强调的多工具、多模态、长流程Agent任务中,其价值还需要结合真实任务成功率进一步观察。
与榜单头部差距仍然存在:当前榜单前列由qwen3.7-max(76.9%)、qwen3.6-max-preview(75.4%)、gpt-5.5(75.3%)、gemini-3.1-pro-preview(75.2%)、gemini-3.5-flash(73.9%)、qwen3.7-plus(73.5%)等模型占据。step-3.7-flash(67.2%)与头部模型存在6至10个百分点左右的差距,更适合作为Flash级开源Agent模型观察,而不是直接对标闭源旗舰。
开源VS闭源对比
开源阵营中的中段位置:在开源模型中,qwen3.5-plus(73.3%)、kimi-k2.6(72.9%)、deepseek-v4-pro(71.7%)、Qwen3.5-122B-A10B(70.9%)、Kimi-K2.5-Thinking(70.8%)、GLM-5.1(70.7%)等模型均高于step-3.7-flash。step-3.7-flash目前更接近Qwen3.6-35B-A3B(68.1%)、GLM-4.7(67.3%)、DeepSeek-V3.2-Think(66.9%)这一段位。
开源与部署生态是重要补充变量:官方披露Step 3.7 Flash同时兼容vLLM、SGLang、Hugging Face Transformers、llama.cpp等推理框架。对于需要本地部署、私有化部署或改造Agent工具链的场景,这类生态兼容性是中文综合榜单之外的重要因素。
3、官方评测
根据阶跃星辰官方博客(https://static.stepfun.com/blog/step-3.7-flash/),Step 3.7 Flash的核心定位是面向真实Agent场景的高效率Flash模型,重点覆盖Agentic Coding、企业任务、搜索、多模态视觉工具、GUI操作以及部署生态。官方评测中的主要信息如下:
Agentic Coding
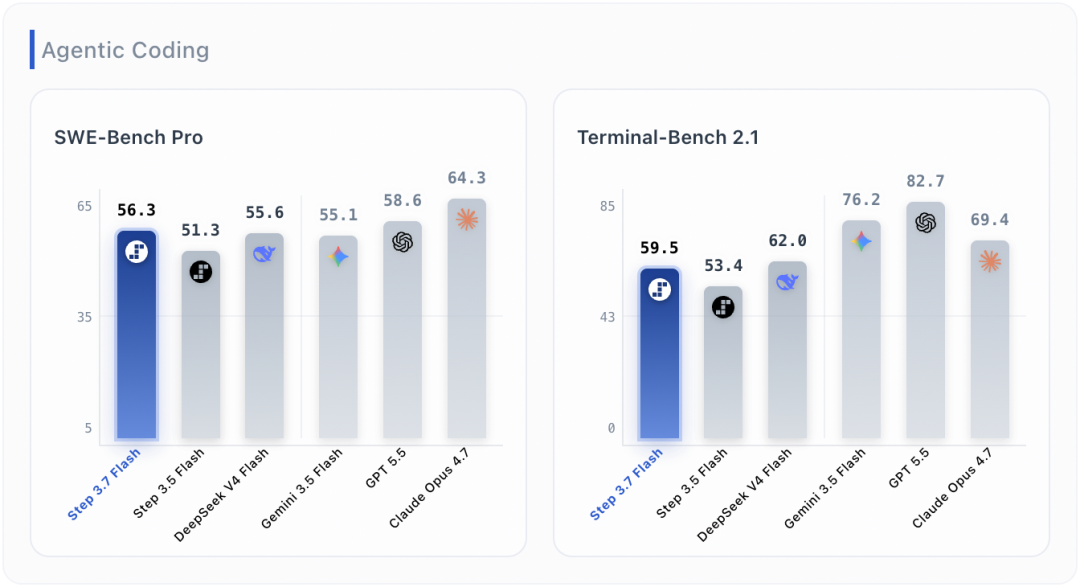
官方数据显示,Step 3.7 Flash在SWE-Bench Pro上取得56.3分,相比Step 3.5 Flash的51.3分有所提升,接近DeepSeek V4 Flash的55.6分和Gemini 3.5 Flash的55.1分,但低于GPT 5.5的58.6分和Claude Opus 4.7的64.3分。在官方同一图表的Terminal-Bench对比中,Step 3.7 Flash取得59.5分,高于Step 3.5 Flash的53.4分,但低于DeepSeek V4 Flash的62.0分、Gemini 3.5 Flash的76.2分、GPT 5.5的82.7分和Claude Opus 4.7的69.4分。需要注意的是,官方说明中提到,GPT 5.5和Claude Opus 4.7使用的是官方自报的Terminal-Bench 2.0成绩,与Step 3.7 Flash的Terminal-Bench 2.1口径并不完全相同。
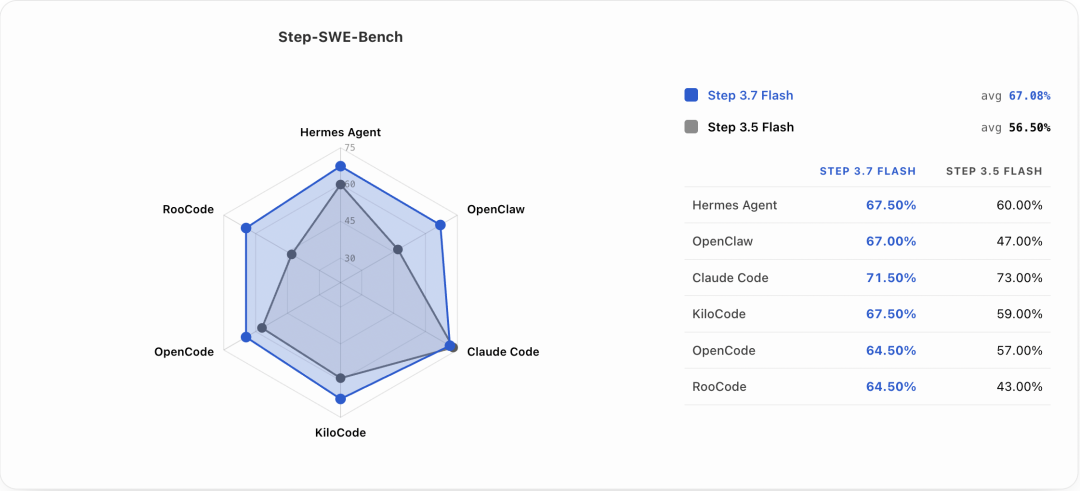
官方还披露了内部Step-SWE-Bench结果:Step 3.7 Flash在Hermes Agent、OpenClaw、Claude Code、KiloCode、OpenCode、RooCode六类框架下平均得分67.08%,Step 3.5 Flash为56.50%。可以注意到,Step 3.7 Flash在不同Agent框架下的表现更均衡,但在Claude Code单项上为71.50%,略低于Step 3.5 Flash的73.00%。
Advisor Mode
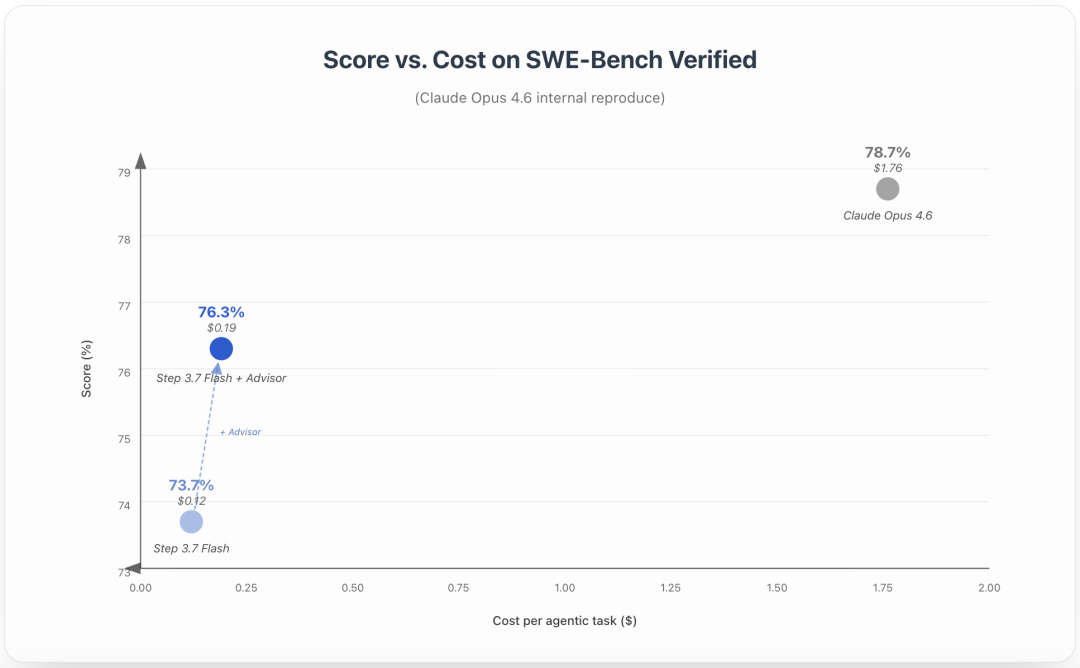
官方介绍,Step 3.7 Flash支持Advisor Mode:由Step 3.7 Flash负责完整执行轨迹,只在规划或多次失败恢复等关键节点向更大的advisor模型咨询。官方给出的SWE-Bench Verified对比中,Step 3.7 Flash为73.7%,每个Agent任务成本为0.12美元;开启Advisor后为76.3%,每任务成本为0.19美元;官方内部复现的Claude Opus 4.6为78.7%,每任务成本为1.76美元。这个结果主要体现了小模型执行器加大模型顾问的混合策略,在Agent任务中的成本效率比空间。
企业任务与工具编排
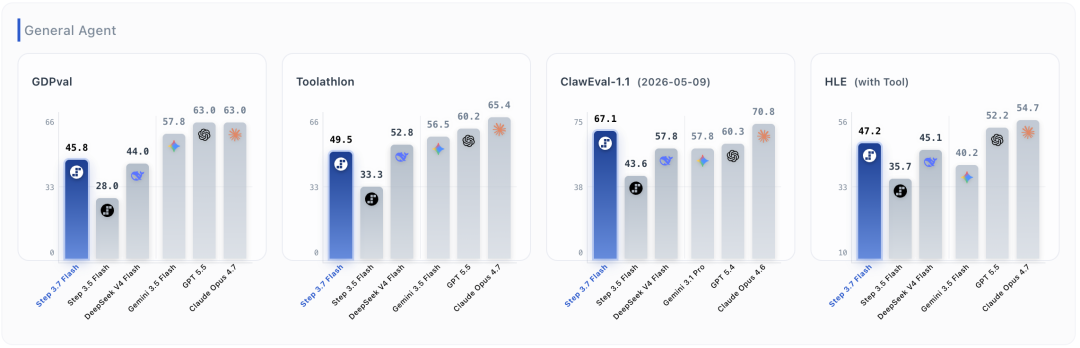
在企业任务和通用Agent能力上,官方披露Step 3.7 Flash在Toolathlon上取得49.5%,在ClawEval-1.1上取得67.1%,在GDPval上取得45.8%。官方还提到,模型可处理截图、复杂文档、表格等混合输入,并在工具编排、任务规划和执行交付上进行了优化。需要注意的是,Toolathlon和GDPval等指标的部分对比模型数据来自官方测试或内部固定版本,直接横向比较时应关注其数据来源差异。
搜索与深度检索
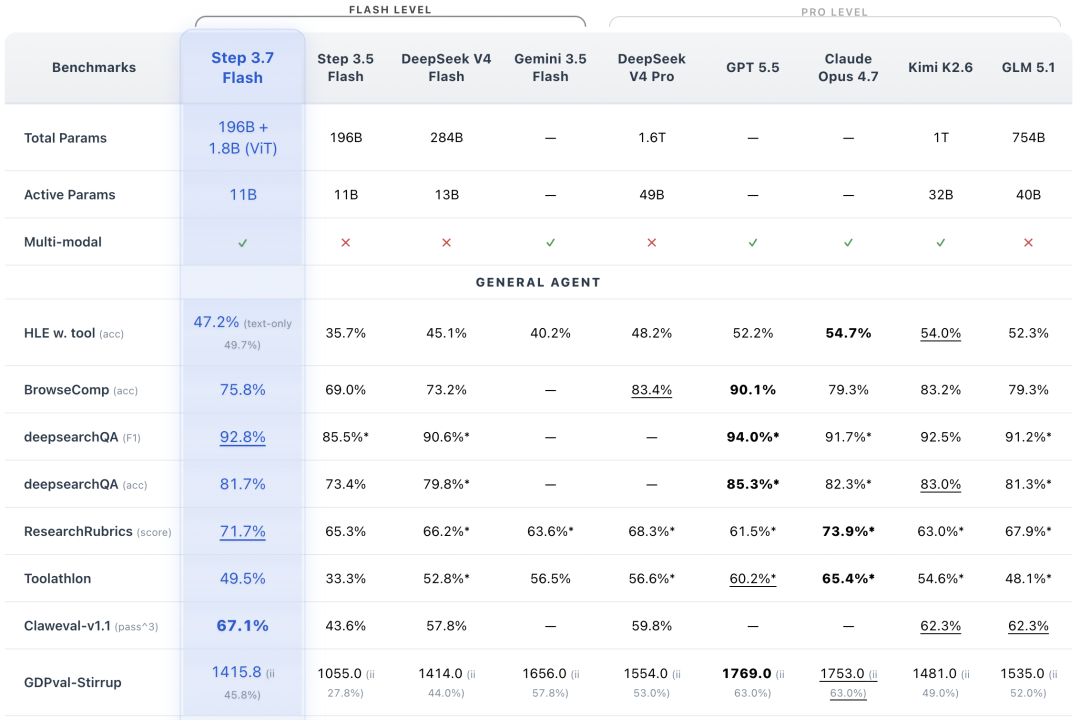
官方将搜索能力作为Step 3.7 Flash的重要方向之一。其披露数据包括:HLE with Tools为47.2%,高于Step 3.5 Flash的35.7%;BrowseComp为75.8%;DeepSearchQA F1为92.8%;ResearchRubrics为71.7%。官方表示,Step 3.7 Flash并非试图把所有知识都压进参数,而是强化搜索规划、证据筛选和信息综合能力。
多模态与视觉工具
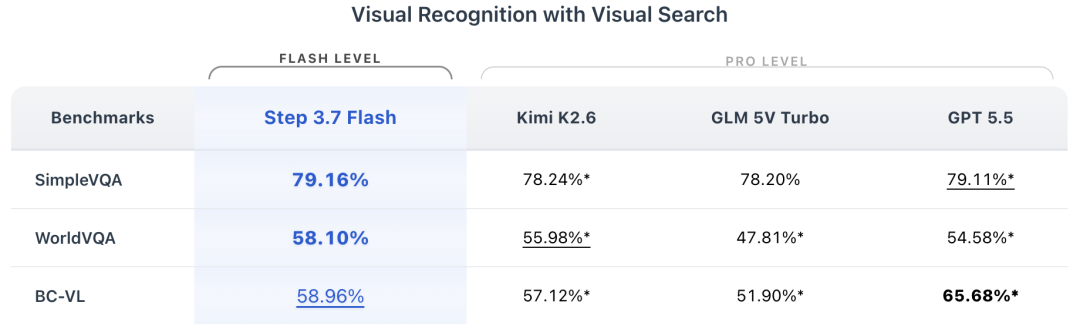
在视觉能力方面,Step 3.7 Flash引入视觉搜索和Python视觉工具。官方数据显示,在SimpleVQA上Step 3.7 Flash为79.16%,WorldVQA为58.10%,BC-VL为58.96%。
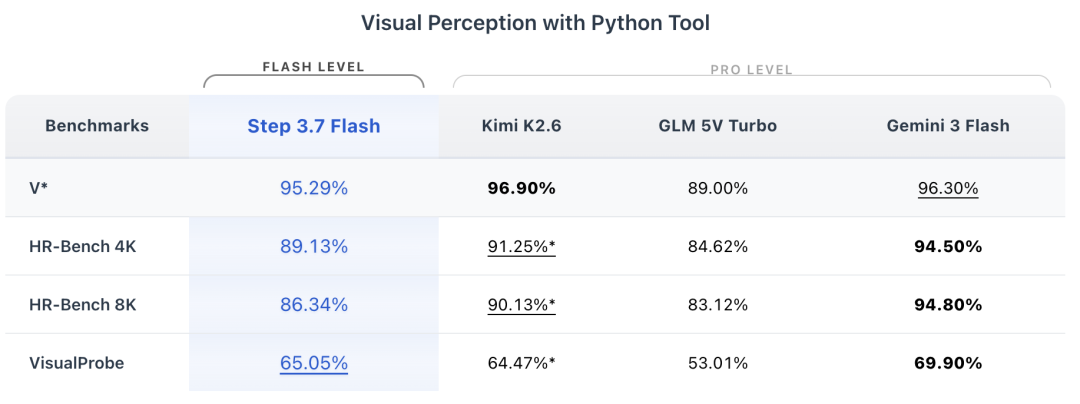
在使用Python工具的视觉感知任务中,V*为95.29%,HR-Bench 4K为89.13%,HR-Bench 8K为86.34%,VisualProbe为65.05%。这些指标说明,官方对Step 3.7 Flash的定位并不是单纯文本模型,而是希望其通过视觉工具参与更复杂的Agent工作流。
GUI操作与部署生态
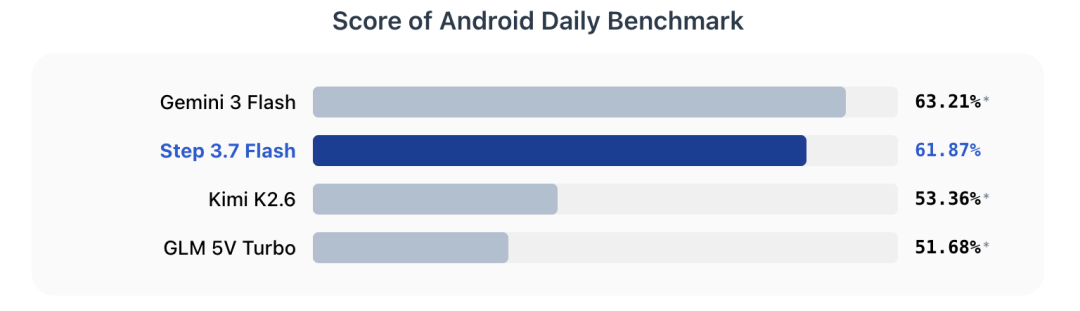
官方还展示了GUI操作能力:在Android Daily Benchmark上,Step 3.7 Flash取得61.87%,低于Gemini 3 Flash的63.21%,高于Kimi K2.6的53.36%和GLM 5V Turbo的51.68%。
非线智能官网https://nonelinear.com 已上线Step 3.7 Flash版,欢迎深度体验。 同时,非线智能API可连接超480+全球模型,支持一键Api聚合以及Api中转,提供稳定的企业级服务。 登录github账号,领20-50元体验金。接入Step 3.7 Flash就用非线智能API。
